1.深度学习
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络如下图所示:
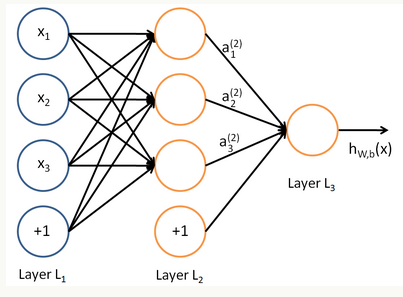
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。最左的层叫做输入层,这层负责接收输入数据,最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层。
隐藏层比较多(大于2)的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法。深层网络和浅层网络相比具有什么优势呢?简单来说深层网络表达力更强。事实上,一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。而深层网络用的少得多的神经元就能拟合同样函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而浅的网络。而后者往往更节约资源。
2.感知器
为了理解神经网络,我们应该先理解神经网络的组成单元———神经元。神经元也叫作感知器。感知器算法在上个世纪50-70年代很流行,也成功解决了很多问题。
2.1感知器的定义
下图是一个感知器。
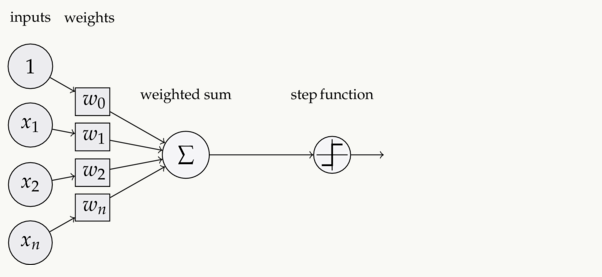
可以看到,一个感知器有如下的组成部分:
-
输入权值 ,一个感知器可以接收多个输入$(x_1,x_2···x_n \mid x_i ∈R)$,每个输入上有一个权值$w_i∈R$,此外还有一个偏置项$b∈R$,就是上图中的$w_0$。
-
激活函数,感知器的激活函数可以又很多选择,比如说我们可以选择下面这个阶跃函数f来作为激活函数:
\[f(z)=\begin{cases} 1 \quad z>0 \\ 0 \quad otherwise \end{cases}\] -
输出 ,感知器的输出由下面这个公式来计算
\[y=f(w*x+b)\quad 公式(1)\]
2.1感知器实现and函数
我们设计一个感知器,让它来实现and运算。下面是它的真值表。
| $x1$ | $x2$ | $y$ |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
为了计算方便,我们用0表示false,用1表示true。
我们令$w1=0.5,w2=0.5,b=-0.8$,而激活函数f就是前面的阶跃函数,这时,感知器就相当于and函数。
输入上面真值表的第一行,即$x1=0;x2=0$,那么根据公式(1),计算输出:
\(\begin{align}y=&f(w*x+b) \\=&f(w_1x_1+w_2x_2+b)\\=&f(0.5*0+0.5*0-0.8)\\=&f(-0.8)\\=&0\end{align}\)
也就是当$x_1x_2$都为0的时候,y为0,这就是真值表的第一行。感知器还能实现or(或)等运算。
2.3感知器还能做什么
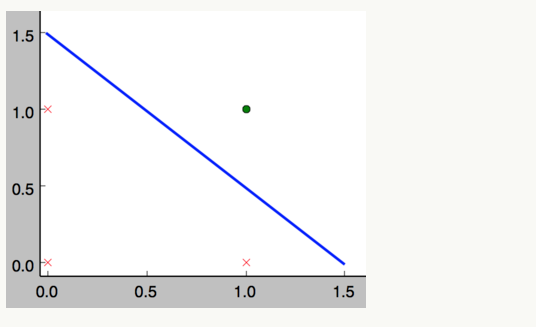
事实上,感知器不仅能实现的简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看做是二分类问题,即给定一个输入,输出0(属于分类0)或 1(属于分类1)。如下面所示,and运算是一个线性分类问题,即可以用一条直线把分类0(false,红叉表示)和分类1(true,绿点表示)分开。
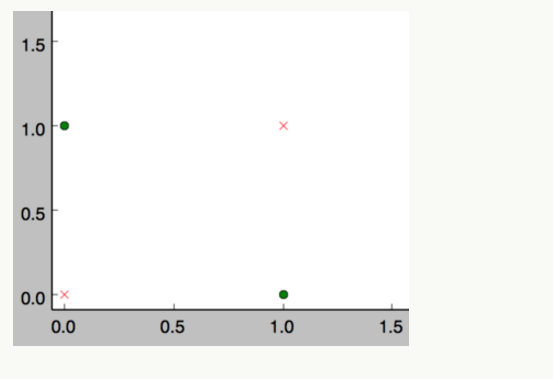
然而感知器却不能实现异或运算,如下图所示,异或运算不是线性的,你无法用一条直线把分类0和分类1分开。
2.4感知器的训练
我们的目的是学习由多个单元互连的网络,但我们还是要从如何学习单个感知器的权值开始。准确的说,这里的学习任务是决定一个权向量,它可以使感知器对于给定的训练样例输出正确的1或-1.
这里我们考虑的方法是感知器法则。感知器法则对于ANN是很重要的,因为它们提供了学习多个单元构成的网络基础。
为得到可接受的权向量,一种方法是从随机的权值开始,然后反复地应用到这个感知器到每个训练样例,只要它误分类样例就修改感知器的权值。重复这个过程,直到感知器正确分类所有的训练样例。每一步根据感知器训练法则来修改权值,也就是修改与输入$x_i$对应的$w_i$,法则如下:
\(w_i←w_i+Δw_i\)
其中:
\(Δw_i=η(t-o)x_i\)
这里t是当前训练样例的目标输出,o是感知器的输出,η是一个正的常数称为学习速率。学习速率的作用是缓和每一步调整权的程度。它通常被设为一个小的数值,而且有时会使其随着权调整次数的增加而衰减。
为什么这个更新法则会成功收敛到正确的权值呢?为了得到直观的感觉,考虑一些特例。假定训练样本已被感知器正确分类。这时,(t-o)是0,这使$Δw_i$为0,所以权值没有被修改。而如果当目标输出是+1时,感知器会输出一个-1,这种情况下为使感知器输出一个+1而不是-1,权值必须被修改以增大$\overrightarrow{w_i}*\overrightarrow{x}$的值。例如,如果$x_i>0$,那么增大$w_i$会使感知器更接近正确分类的这个实例。注意,这种情况下训练法则会增长$w_i$,因为$(t-o).η和x_i$都是正的。例如,如果$x_i=0.8,η=0.1,t=1$,并且$o=-1$,那么权更新就是$Δw_i=η(t-o)x_i=0.1(1-(-1))0.8=0.16$。另一方面,如果$t=-1而o=1$,那么和正的$x_i$关联的权值会被减小而不是增大。
事实上可以证明,在有限次的使用感知器训练法则后,上面的训练过程会收敛到一个能正确分类所以训练样例的权向量,前提是训练样例线性可分,并且使用了充分小的$η$.如果数据不是线性可分的,那么不能保证训练过程收敛。