线性单元
感知器有一个问题,当面对的数据集不是线性可分的时候,感知器法则可能无法收敛,这意味着我们永远无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
为了简单起见,我们可以设置线性单元的激活函数f为
\(f(x)=x\)
这样的线性单元如下图所示
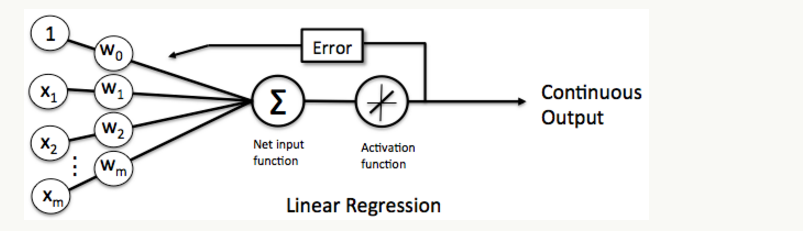
对比之前我们讲过的感知器
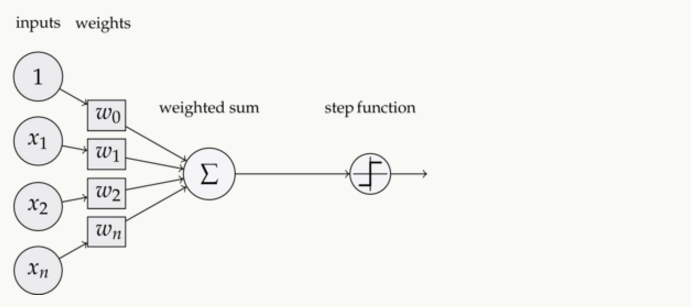
这样替换了激活函数f之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
线性单元的模型
当我们说模型时,我们实际上在谈论根据输入x预测输出y的算法。比如,x可以是一个人的工作年限,y可以是他的月薪,我们可以用某种算法来根据一个人的工作年限来预测他的收入。比如:
\(y=h(x)=w*x+b\)
函数h(x)叫做假设,而w,b是它的参数。我们假设$参数w=1000,参数b=500$,如果一个人的工作年限是5年的话,我们的模型会预测他的月薪为:
\(y=h(x)=1000*5+500=5500\)
你也许会说,这个模型太不靠谱了。是这样的,因为我们考虑的因素太少了,仅仅包含了工作年限。如果考虑更多的因素,比如所处的行业、公司、职级等等,可能预测就会靠谱的多。我们把工作年限、行业、公司、职级这些信息,称之为特征。对于一个工作了5年,在IT行业,百度工作,职级T6这样的人,我们可以用这样的一个特征向量来表示他。
x=(5,IT,百度,T6)。
既然输入x变成了一个具备四个特征向量,相对应的,仅仅一个参数$ω$就不够用了,我们应该使用4个参数$ω_1,ω_2,ω_3,ω_4$,每个特征对应一个。这样,我们的模型就变成
\[y=h(x)=ω_1*x_1+ω_2*x_2+ω_3*x_3+ω_4*x_4+b\]其中,$x_1$对应工作年限,$x_2$对应行业,$x_3$对应公司,$x_4$对应职级。
我们还可以把上式写成向量模式
\[y=h(x)=W^TX\quad(式1)\]长成这种样子模型叫做线性模型,因为输出y就是输入特征$x_1,x_2···$的线性组合。
监督学习和无监督学习
接下来,我们需要关心的是这个模型如何训练,也就是参数w取什么值最合适。
机器学习有一类学习方法叫做监督学习,它是为了训练一个模型,我们需要提供这样一堆训练样本:每个训练样本既包括输入特征x,也包括对应的输出y(y也叫作标记)。也就是说,我们要找到很多人,我们既知道他们的特征,也知道他们的收入。我们用这样的样本去训练模型,让模型既看到我们提出的每个问题(输入特征x),也看到对应问题的答案(标记y)。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
另一类学习方法叫做无监督学习,这种方法的训练样本只有x而没有y。模型可以总结出特征x的一些规律,但是无法知道对应的答案y。
线性单元的目标函数
这里,我们只考虑监督学习。在监督学习下,对于一个样本,我们知道它的特征x,以及标记y。同时,我们还可以根据模型h(x)计算得到的输出y。注意这里面我们用y表示训练样本里面的标记,也就是标记值;用带上划线的$\overrightarrow{y}$表示模型计算出来的预测值。我们当然希望模型计算出来的$\overrightarrow{y}和y$越接近越好。
数学上有很多方法来表示$\overrightarrow{y}和y$的接近程度,比如我们可以用$\overrightarrow{y}和y$的差的平方的$\frac{1}{2}$来表示它们的接近程度。
\(E(\overrightarrow{w})=\frac{1}{2} \sum^{n}_{i=1}(y-\overrightarrow{y})^2\quad (式2)\)
我们当然希望对于一个训练数据集来说,误差越小越好,也就是式(2)的值越小越好。对于特定的训练数据来说,$(x^{(i)},y^{(i)}$)的值都是已知的,所以式(2)其实是参数w的函数。由此可见,模型的训练,实际上就是求取合适的w,使式(2)取得最小值。这在数学上称作优化问题,而$E(\overrightarrow{w})$就是我们优化的目标,称之为目标函数。
梯度下降
为了确定一个使E最小化的权向量,梯度下降搜索从一个任意的初始权向量开始,然后以很小的步伐反复修改这个变量。每一步都是沿误差曲面产生最陡峭下降的方向修改向量,继续这个过程直到得到全局的最小误差点。
我们怎样才能计算出沿误差曲面最陡峭下降的方向呢?可以通过计算E相对向量$\overrightarrow w$的每个分量的倒数来得到这个方向。这个向量导数被称为E对于$\overrightarrow w$的梯度,记作$\bigtriangledown E(\overrightarrow w)$.
\[\bigtriangledown E(\overrightarrow w)=\lgroup \frac{δE}{δw_0},\frac{δE}{δw_1},···\frac{δE}{δw_n}\rgroup \quad(3)\]注意$\bigtriangledown E(\overrightarrow w)$本身是一个向量,它的成员是E对每个$w_i$的偏导数。当梯度被解释为全空间的一个向量时,它确定了使E最陡峭上升的方向。所以这个向量的反方向给出了最陡峭下降的方向。
既然梯度确定了E最陡峭上升的方向,那么梯度下降的训练法则是:
\[\overrightarrow w←\overrightarrow w+Δ \overrightarrow w\]其中:
\[Δ\overrightarrow w=-\eta \bigtriangledown E(\overrightarrow w) \quad(4)\]这里的$\eta$是一个正的常数叫做学习速率,它决定梯度下降搜索的步长。公式中的负号是因为我们想让权向量向E下降的方向移动。这个训练法则也可以写成它的 分量形式:
\[w_i←w_i+Δw_i\]其中:
\[Δw_i=- \eta \frac {δE}{δw_i} \quad(5)\]这样很清楚,最陡峭的下降可以按照比例$\frac{δE}{δw_i}$改变$\overrightarrow w$中的每一个$w_i$来实现。
要形成一个根据公式(5)迭代更新权的使用算法,我们需要一个高效的方法在每一步都计算这个梯度。幸运的是计算过程并不困难。我们可以从式(2)中计算E的微分,从而得到组成这个梯度向量的分量$\frac{δE}{δw_i}$。过程如下:
\[\begin{align} \frac{δE}{δw_i}=&\frac{δ\frac{1}{2} \sum^n_{i=1}(y-\overrightarrow{y})^2}{δw_i}=\frac{1}{2} \sum^n _{i=1}\frac{δ(y-\overrightarrow{y})^2}{δw_i}\\&=\frac{1}{2}\sum^n_{i=1}2(y-\overrightarrow{y})\frac{δ(y-\overrightarrow{y})}{δw_i} \\ &=\sum^n_{i=1}(y-\overrightarrow{y})\frac{δ(y-\overrightarrow w_i*\overrightarrow x_d)}{δw_i} \end{align}\] \[\frac{δE}{δw_i}=\sum^n_{i=1}(y-\overrightarrow{y})(-x_{id}) \quad (6)\]其中,$x_{id}$表示训练样例d的一个输入 分量$x_i$。现在我们有了一个公式,能够用线性单元的输入$x_{id}$、输出$o_d$以及训练样例的目标值$t_d$表示$\frac{δE}{δw_i}$。把公式(6)代入到公式(5)便得到了梯度下降权值更新法则。
\[Δ w_i=\eta \sum^n_{i=1}(y-\overrightarrow{y})x_{id}\quad(7)\]总而言之,训练线性单元的梯度下降算法如下:选取一个初始的随机权向量;应用线性单元到所有的训练样例,然后根据公式(7)计算每个权值$Δw_i$;通过加上$Δw_i$来更新每个权值,然后重复这个过程。
随机梯度下降算法
如果我们根据$E=e^(1)+e^(2)+···+e^(n)$来训练模型,那么我们每次更新w的迭代,要遍历训练数据中的所有的样本进行计算,我们称这种算法叫做批梯度下降。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新w的迭代,只计算一个样本,这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新w并不一定按照减少E的方向。然而,虽然存在一定随机性,大量更新总体沿着减少E的方向前进的,因此最后也能收敛到最小值附近。
最后需要说明的是,SGD不仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个凸函数,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
小结
在机器学习中,算法往往并不是关键,真正的关键之处在于选取特征。选取特征需要我们人类对问题的深刻理解,经验,以及思考。而神经网络算法的一个优势,就在于它能够自动学习到应该提取什么特征,从而使算法不再那么依赖人类,而这也是神经网络之所以吸引人的一个方面。