最近在看张重生著的《深度学习》这本书,看到神经网络这一章,顿时恍然大悟,发现自己对神经网络这一块有了新的理解和感受。于是写下这篇笔记,加深自己的体会。
神经网络的神经网络是一种经典的机器学习算法,随着对神经网络研究的不断深入,目前,它在模式识别、物体检测、视频分析和图像识别领域等领域发挥着越来越重要的作用。
1.神经元的概念
神经元是构成神经网络的基本单元,其基本模型如图(1)所示。
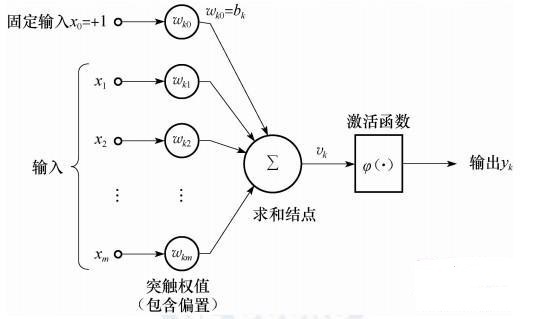
图(1)
可以表示为\(y_{k}=f(\sum_{i=1}^n w_{ik}×x_{i}+b_{k})\)
其中$f(·)$可以是sigmoid函数($f(x)=\frac{1}{1+e^{-x}}$,域值范围为[0,1]),也可以双曲线正切
($f(x)=\frac{e^{x}-e^{x}}{e^{x}+e^{-x}}$),域值范围为[-1,1])等非线性函数。sigmoid函数被看成一个挤压函数,它可以将一个较大输入范围挤压到较小的0~1的区域。sigmoid函数和双曲线正切函数的函数图像见图(2)。$y_{k}$的值是由输入和对应的权值进行线性求和,然后再加上偏置值$b_{k}$,在使用激活函数$f(·)$获得的。
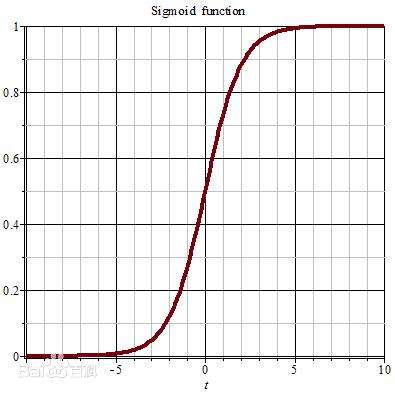
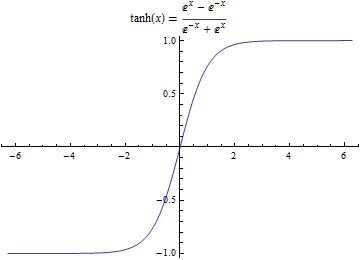
图(2)
2.神经网络
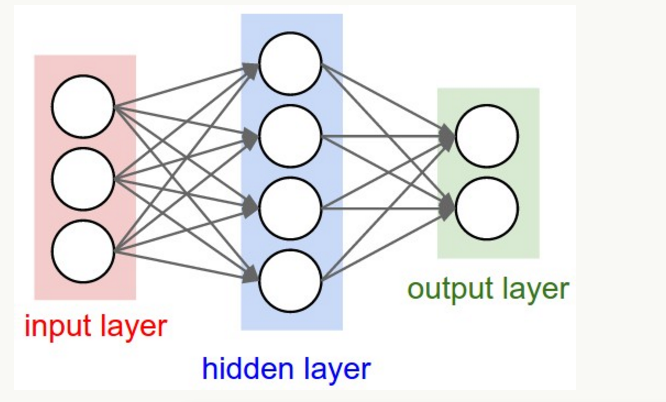
神经网络其实就是按照一定规则连接起来的多个神经元。下图展示了一个全连接(full connected ,FC)神经网络,通过观察上面的图,我们可以发现它的规则包括:
-
神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们以可以从这层获取神经网络输出数据。输出层和输入层之间的层叫做隐藏层,因为它们对于外部来说是不可见的
-
同一层的神经元之间没有;连接。
-
第N层的每个神经元和第N-1层 的所有神经元相连(这就是全连接的含义),第N-1层神经元的输出就是第N层神经元的输入
-
每个连接都有一个权值
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其他结构的神经网络,比如卷积神经网络(CNN) ,循环神经网络(RNN) ,他它们都具有不同的连接规则。
计算神经网络的输出
神经网络实际上就是一个输入向量$\overrightarrow{x}$到输出向量$\overrightarrow{y}$的函数,即:
\(\overrightarrow{y}=f_{network}(\overrightarrow{x})\)
根据输入计算神经网络的输出,需要首先将输入向量$\overrightarrow{x}$的每个元素$x_i$的值赋给神经网络的输入层的对应神经元,然后根据式$y=sigmoid(x)$依次向前计算每一层的每个神经元的值,直到最后一层输出层的所有神经元的值计算完毕。最后,将输出层每个神经元的值串在一起就得到了输出向量$\overrightarrow{y}$。
如果神经网络中的隐藏层足够多,该神经网络可以逼近任何函数。但由于网络结构比较负载,会造成过拟合现象,或在误差后向传播过程中产生梯度弥散现象。
3.后向传播算法
神经网络的训练包括正向传播和反向传播两个过程。正向传播是输入信号从输入层,经过若干隐藏层,从输出层输出结果(预测)的过程;误差后向传播算法是将误差信号从输出层反向传播至输入层的过程。反向传播主要使用误差后向传播(EBP)算法和梯度下降对网络各层调整权重,通过比较输出信号和期望信号得到误差信号,利用链式求导将误差信号逐层向前传播得到各层误差信号,根据各层误差信号调整各层权重和相关参数。而不断调整权重和相关参数的过程就是人工神经网络训练学习的过程。
我们希望网络的输出尽可能的接近真正想要的预测值。那么就可以通过比较当前网络的预测值和我们想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,指导能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数,用于衡量预测值和目标值的差异方程。损失函数的输出值越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小损失的过程。所用的方法是梯度下降:通过使损失值向当前点对于梯度的反方向不断移动,来降低损失。一次移动多少是由学习速率来控制的。
假设第i个单元与第j个单元有链接,则相关符号说明如下:
$b_j$ 表示与第j个单元相关的偏置值;
$I_j=(\sum_{i}w_{ij}O_j+b_j)$表示第j个单元的输入值;
$O_j$表示第j个单元的输出值;
$f(·)$表示神经元激活函数;
$w_{ij}$表示第i个单元与第j个单元之间的权值;
$b_i$表示与第i个神经单元相关的偏置值;
$λ$表示学习速率;
$δ_{i}$表示与第i个神经元相关的误差项;
$nextlayer(j)$表示下一层中与第j个神经单元相连的神经单元集合。
使用sigmoid激活函数的神经网络的后向传播算法整体思想如下。
while不满足终止条件{
遍历训练集中的每一个样例:
#1.将每个训练样例输入沿着网络向前传播计算:
输入层没有计算操作,所以输入层的输出等于输入:
$O_j=I_j$ (3.2)
隐藏层或输出层输出:
$I_j=(\sum_{i}w_{ij}O_j+b_j)$ //根据与单元j相连的单元,计算单元j的输入
$O_j=f(I_j)$//使用激活函数(sigmoid函数)计算单元j的输出 (3.3)
#2.使用误差项后向传播
输出单元j误差项的计算:
\(δ_j=O_j×(1-O_j)×(T_j-O_j)\) (3.4)
隐藏单元j误差项的计算:
\(δ_j=O_j×(1-O_j)×\sum_{k∈nextplayers}×δ_k×w_{jk}\)//k为下一层与隐藏单元j相连的单元 (3.5)
权重更新
\(△w_{ij}=λ×δ_{j}×O_i\)
\(w_{ij}=w_{ij}+△w_{ij}\) (3.6)
偏置更新
\(△b_j=λ×δ_j\)
b_j=b_j+△b_j (3.7)
}
上面算法中的终止条件为认为设定条件,可以是达到指定的迭代次数,也可以是网络收敛到一定程度等。终止条件的选择至关重要,例如终止条件为迭代次数时,迭代次数过少,网络误差降低幅度很小;迭代次数过多,有可能会导致网络出现过拟合现象。
4.后向传播算法的推导
本节主要介绍后向传播算法的推导过程,让读者更清晰地了解权值和偏置更新。假设某个样例为d,该样例对应的误差项为$E_{d}$,则$E_{d}$的计算公式为
\(E_{d}=\frac{1}{2}\sum_{m \in outs}(T_m-O_m)^2\quad (3.8)\)
其中,outs表示输出层中输出单元的集合。$O_m$表示第m个单元,$T_m$表示样例d的第m个单元对应的真实目标值。
权重改变量$Δw_{ij}$和偏置改变量$Δb_j$为:
\(\begin{align} Δw_{ij}=&-λ*\frac{δE_{d}}{δw_{ij }}\\=&- λ*\frac{δE_d}{δI_j}*\frac{δI_j}{δw_{ij}}\\=&- λ*\frac{δE_d}{δI_j}*\frac{δ(w_{ij}*O_i+b_j)}{δw_{ij}}\\=&- λ*\frac{δE_d}{δI_j}*O_i\end{align}\quad (3.9)\)
\(\begin{align}Δb_j=&-λ*\frac{δE_d}{δb_j}\\=&-λ*\frac{δE_d}{δI_j}*\frac{δI_j}{δb_j} \\=&- λ*\frac{δE_d}{δI_j}*\frac{δ(w_{ij}*O_i+b_j)}{δb_{j}}\\=&- λ*\frac{δE_d}{δI_j}\end{align}\quad 式(3.10)\)
(1)输出单元的权值和偏置更新策略
由链式求导法则可知:
\(\frac{δE_d}{δI_j}= \frac{δE_d}{δO_j} * \frac{δO_j}{δI_j}\quad(3.11)\)
式(3.4)中,只有当k=j时,$\frac{δ(\frac{1}{2} \sum_{k \in {outs}}(T_k-O_k)^2)}{δO_j}≠0,$则
\(\begin{align}\frac{δE_d}{δO_j}=&\frac{δ(\frac{1}{2} \sum_{k \in {outs}}(T_k-O_k)^2)}{δO_j}\\=&\frac{1}{2} \frac{δ(T_j-O_j)^2}{δO_j}\\=&-(T_j-O_j)\end{align}\quad (3.12)\)
由于$O_j=f(I_j),$则
\(\begin{align} \frac{δO_j}{δI_j}=&(I_j)*(1-f(I_j))\\=&O_j*(1-O_j) \end{align}\quad (3.13)\)
由式(3.7)和式(3.8)可得,
\(\begin{align}\frac{δE_d}{δI_j}=&\frac{δE_d}{δO_j}*\frac{δO_j}{δI_j}\\=&-O_j*(1-O_j)*(T_j-O_j)\end{align}\quad (3.14)\) 从而可得,第j个单元误差项的值为:
\(\begin{align}δ_j=&-\frac{δE_d}{δI_j}\\=&O_j*(1-O_j)*(T_j-O_j)\end{align}\quad (3.15)\)
(2)隐藏单元的权值和偏置更新策略
隐藏单元j的误差项主要由与它连接的下一层的所有单元的误差项决定。因此可通过以下方式进行计算。
\(\begin{align} \frac{δE_d}{δI_j}=&\sum_{k \in nextlayer(j)}\frac{δE_d}{δI_k}*\frac{δI_K}{δI_j}\\=&\sum_{k \in nextlayer(j)}(-δ_k)*\frac{δI_k}{δI_j}\\=&\sum_{k \in nextlayer(j)}(-δ_k)*\frac{δI_k}{δO_j}*\frac{δO_j}{δI_j}\\=&\sum_{k \in nextlayer(j)}(-δ_k)*\frac{w_{jk}O_j+b_k}{δO_j}*\frac{δO_j}{δI_j}\\=&\sum_{k \in nextlayer(j)}(-δ_k)*w_{jk}*\frac{δO_j}{δI_j}\\=&\sum_{k \in nextlayer(j)}(-δ_k)*w_{jk}*O_j*(1-O_j)\end{align}\quad (3.16)\)
从而可得,第j个单元的误差项的值为:
\(\begin{align}δ_j=&-\frac{δE_d}{δI_j}\\=&O_j*(1-O_j)*\sum_{k \in nextlayer(j)}δ_k*w_{jk}\end{align}\quad (3.17)\)
由式(3.9),式(3.10),式(3.15)和式(3.17)可知: \(Δw_{ij}=λ×δ_j×O_i\)
\(Δb_j=λ×δ_j\)
5.神经网络算法示例
这里我们讲解单样本输入时的计算过程。设输入样例为${x_1.x_2,x_3,x_4}={1,0,1,1}$,学习速率$l=0.8$,真实标签为1,神经网络结构示例如上图(3)所示,网络中相关权重和偏置信息如表2-1所示。
表2-1网络中相关权重和偏置信息
| $w_{15}$ | 0.5 | $w_{46}$ | 0.5 |
|---|---|---|---|
| $w_{16}$ | 0.2 | $w_{47}$ | -0.1 |
| $w_{17}$ | -0.5 | $w_{58}$ | 0.6 |
| $w_{25}$ | -0.2 | $w_{68}$ | -0.2 |
| $w_{26}$ | 0.3 | $w_{78}$ | 0.1 |
| $w_{27}$ | 0.4 | $b_{5}$ | 0.2 |
| $w_{35}$ | 0.8 | $b_{6}$ | -0.5 |
| $w_{36}$ | -0.6 | $b_7$ | 0.4 |
| $w_{37}$ | 0.4 | $b_8$ | 0.6 |
| $w_{45}$ | 0.6 |
根据式(3.2)和式(3.3)可以计算网络中每个单元的输入和输出值,如表2-2所示。
表2-2网络每个单元的输入和输出
| 神经单元 | 输入I | 输出O |
|---|---|---|
| $x_1$ | 1 | 1 |
| $x_2$ | 0 | 0 |
| $x_3$ | 1 | 1 |
| $x_4$ | 1 | 1 |
| $x_5$ | 1×0.5+0×(-0.2)+1×0.8+1×0.6+0.2=2.1 | $\frac{1}{1+e^{-2.1}}=0.8909$ |
| $x_6$ | 1×0.2+0×0.3+1×(-0.6)+1×0.5-0.5=0.4 | $\frac{1}{1+e^{0.4}}=0.40131$ |
| $x_7$ | 1×(-0.5)+0×0.4+1×0.4+1×(-0.1)+0.4=0.2 | $\frac{1}{1+e^{-0.2}}=0.54983$ |
| $x_8$ | 0.8909×0.6+0.40131×(-0.2)+0.54983×0.1+0.6=1.1093 | $\frac{1}{1+e^{-1.1093}}=0.752$ |
根据式(3.4)和式(3.5)可以计算网络中每个单元的误差项的值,如表2-3所示。
表2-3 网络中每个单元的误差项的值
| 神经单元 | 误差项$δ$ |
|---|---|
| $δ_{x8}$ | 0.752×(1-0.752)×(1-0.752)=0.04625 |
| $δ_{x7}$ | 0.54982×(1-0.54983)×(0.1×0.04625)=0.0011448 |
| $δ_{x6}$ | 0.40131×(1-0.40131)×(-0.2×0.04625)=-0.0022224 |
| $δ_{x5}$ | 0.8909×(1-0.8909)×(0.6×0.04625)=0.0026972 |
根据式(3.6)和式(3.7)可以计算网络中更新后的权重值和偏置值,如表2-4
表2-4 网络中更新后的权重值和偏置值
| 权重和偏置 | 更新后的值 |
|---|---|
| $w_{15}$ | 0.5+0.8×0.0026972×1=0.50216 |
| $w_{16}$ | 0.2+0.8×(-0.0022224)×1=0.19822 |
| $w_{17}$ | (-0.5)+0.8×0.0011448×1=0.49908 |
| $w_{25}$ | (-0.2)+0.8×0.0026972×0=-0.2 |
| $w_{26}$ | 0.3+0.8×(-0.002224)×0=0.3 |
| $w_{27}$ | 0.4+0.8×0.0011448×0=0.4 |
| $w_{35}$ | 0.8+0.8×0.0026972×1=0.80216 |
| $w_{36}$ | (-0.6)+0.8×(-0.0022224)×1=-0.60178 |
| $w_{37}$ | 0.4+0.8×0.0011448×1=0.40092 |
| $w_{45}$ | 0.6+0.8×0.0026972×1=0.60216 |
| $w_{46}$ | 0.5+0.8×(-0.002224)×1=0.49822 |
| $w_{47}$ | (-0.1)+0.8×0.0011448×1=-0.099084 |
| $w_{58}$ | 0.6+0.8×0.04625×0.8909=0.63296 |
| $w_{68}$ | (-0.2)+0.8×0.04625×0.40131=-0.18515 |
| $w_{78}$ | 0.1+0.8×0.04625×0.54983=0.12034 |
| $b_{5}$ | 0.2+0.8×0.0026972=0.20216 |
| $b_{6}$ | (-0.5)+0.8×(-0.0022224)=-0.50178 |
| $b_{7}$ | 0.4+0.8×0.0011448=0.40092 |
| $b_{8}$ | 0.6+0.8×0.04625=0.637 |