信息熵
一条信息的信息量与其不确定性有着直接关系。比如说,我们要搞清楚一件非常非常不确定的事情,或是我们一无所知的事情,就需要了解大量的信息。相反,如果对某件事了解比较多,则不需要太多的信息就能把它搞清楚。所以,从这个角度来看,可以认为信息量就是等于不确定性的多少。
那么如何量化信息量的度量呢?来看一个例子。2014举行了世界杯足球赛,大家都会很关心谁是冠军。假如我错过了看世界杯,赛后我问一个知道比赛结果的观众“那支球队是冠军”?他不愿意直接告诉我,而是让我猜,并且我每猜一次,他要收一元钱才肯告诉我是否猜对了,那么我要掏多少钱才能知道谁是冠军呢?我可以把球队编上号,从1到32,然后提问:“冠军队在1到16号中吗?”假如他告诉我猜对了,我会接着问:“冠军在1到8号中吗?”假如他告诉我猜错了,我自然知道冠军队在9到16号中。这样只需要五次,我就能知道哪支球队是冠军。所有,谁是世界杯冠军这条信息量只值5块钱。
当然香农不是用钱,而是用“比特”(Bit)这个概念来度量信息量。一个比特就是一位二进制数,在计算机中,一个字节是8比特。在上面的例子中,这条消息的信息量是5比特。(如果有朝一日有64支球队进入决赛阶段的比赛,那么“谁是世界杯冠军”的信息量就是6比特,因为要多猜一次。)读者可能已经发行,信息量的比特数和所有可能的情况的对数函数log有关。
有些读者会发现实际上可能不需要猜五次就能猜出谁是冠军,因为像西班牙、巴西、德国、意大利这样的球队夺得冠军的可能性比日本、南非、韩国等球队大得多。因此,第一次猜测时不需要把32支球队等分成两个组,而可以把少数的几支最可能的球队分成一个组,把其他球队分成另外一个组。然后猜冠军球队是否在那几支热门球队中。重复这样的过程,根据夺冠概率对余下候选球队分组,直到找到冠军。这样,也许三次或四次就猜出结果。因此,当每支球队夺冠的可能性(概率)不等时,“谁是世界杯冠军”的信息量比5比特少。香农指出,它的准确信息量应该是
\(H=-(p_1logp_1+p_2logp_2+···+p_{32}logp_{32})\)
其中,$p_1,p_2,···p_{32}$分别是这32支球队夺冠的概率。香农把它称为“信息熵”,一般用符号$H$表示,单位是比特。当32支球队夺冠概率相同时,对应的信息熵等于5比特。
有了“熵”这个概念,就可以回答文本开始提出的问题,即一本50万字的中文平均有多少信息量。我们知道常用的汉字(一级二级国标)大约7000字。假如每个汉字等概率,那么大约需要13比特(即13位二进制数)表示一个汉字。但汉字的使用频率不是均等的。实际上,前10%的汉字占用文本的95%以上。因此,即使不考虑上下文的相关性,而只考虑每个汉字的独立概率,那么,每个汉字的信息熵就只有5比特左右。所以,一本书50万字的中文书,信息量大约是250万比特。采用比较好的算法进行压缩,整本书可以存成一个320KB的文件。如果直接用两字节的国标编码存储这本书,大约需要1MB大小,是压缩文件的三倍。这两个数量的差距,在信息论中称作“冗余度”。不同语言的冗余度差别大,而汉语在所有语言中冗余度是相对小的。
信息的作用
自古以来,信息和消除不确定性是相联系的。在英语里,信息和情报是同一个词,而我们知道情报的作用就是排除不确定性。接下来,我们将信息论原理抽象化、普遍化,可以总结如下:
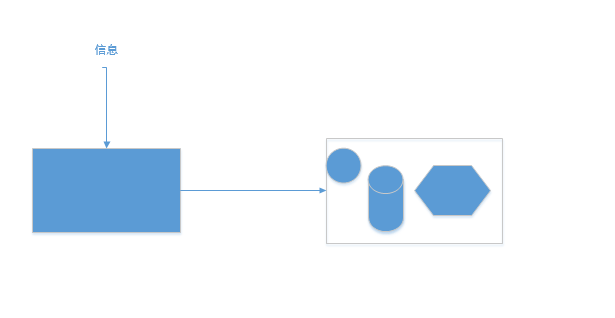
上图 信息是消除系统不确定性的唯一办法(在没有获得任何信息之前,一个系统就像是一个黑盒子,引入信息,就可以了解黑盒子系统的内部结构)
一个事物内部会存有随机性,也就是不确定性,假定为$U$,而从外部消除这个不确定性唯一的办法是引入信息$I$,而需要引入的信息量取决于这个不确定性的大小, 即$I>U$才行。当$I<U$时,这些信息可以消除一部分不确定性,也就是说新的不确定性。也就是新的不确定性。
\(U_1=U-I\)
反之,如果没有信息,任何公式或者数字的游戏都无法排除不确定性。
知道的信息越多,随机事件的不确定性就越小。这些信息,可以是直接针对我们要了解的随机事件,也可以是和我们关心的随机事件相关的其他(事件)的信息—通过获取这些相关信息也能帮助我们了解所关注的现象。比如自然语言的统计模型,其中的一元模型就是通过某个词本身的概率分布,来消除不确定因素;而二元及更高阶的语言模型则还使用了上下文的信息,那就能准确预测一个句子中的当前词汇了。在数学上可以严格地证明为什么这些“相关的”信息也能够消除不确定性。为此,需要引入一个条件熵的概念。
假定$X$和$Y$是两个随机变量,$X$是我们需要了解的。假定我们现在知道了$X$的随机分布$P(X)$,那么也知道了$X$的熵:
\(H(x)=-\sum _{x \in X}P(x)*log P(x)\)
那么它的不确定性就是这么大。现在假定我们还知道$Y$的一些情况,包括它和$X$一起出现的概率,在数学上称为联合概率分布,以及在$Y$取不同值的前提下$X$的概率分布,在数学上称为条件概率分布。定义在$Y$的条件下的条件熵为:
\(H(X \mid Y)=-\sum _{x\in X,y \in Y}log P(x \mid y)\)
互信息
我们在上一节中提到,当获取的信息和要研究的事物“有关系”时,这些信息才能帮助我们消除不确定性。当然“有关系”这种说法太模糊,太不科学,最好能够量化地度量“相关性”。比如常识告诉我们,一个随机事件“今天北京下雨”和另一个随机变量“过去24小时北京空气的湿度”的相关性就很大,但是它们的相关性到底有多大?在比如“过去24小时北京空气的湿度”似乎就和“旧金山的天气”相关性不大,但我们能否说它们毫无相关性?为此,香农在信息论中提出了一个“互信息”的概念作为两个随机事件“相关性”的量化度量。
假定有两个随机事件$X$和$Y$,它们的互信息定义如下:
\(I(X;Y)=\sum_{x \in X,y\in Y}P(x,y)log \frac{P(x,y)}{P(x)P(y)}\)
很多见了公式就头大的读者看了这个定义可能会感到有点烦。不过没关系大家只要记住这个符号$I(X;Y)$就好。我们接着会证明,其实这个互信息就是上节介绍的随机事件$X$的不确定性或者熵$H(X)$,以及在知道随机事件$Y$条件下的不确定性,或者说条件熵$H(X\mid Y )$之间的差异,即
\(I(X;Y)=H(X)-H(X \mid Y)\)
现在清楚了了,所谓两个事件相关性的量化度量,就是在了解了其中一个$Y$的前提下,对消除另一个$X$不确定性所提供的信息量。需要讲一下,互信息是一个取值在0到$min(H(X),H(Y))$之间的函数,当$X$和$Y$完全相关时,它的取值是1;当二者完全无关时,它的取值是0。
在自然语言处理中,两个随机事件,或者语言特征的互信息是很容易计算的。只要有足够的语料,就不难估计出互信息公式中的$P(X,Y),P(X)$和$P(Y)$三个概率,进而算出互信息。因此,互信息就广泛用于度量一些语言现象的相关性。
机器翻译中,最难的两个问题之一是词义的二义性(又称歧义性)问题。比如Bush一词可以是美国总统布什的名字,也可以是灌木丛。(有一个笑话,2004年和布什争夺总统的民主党候选人克里的名字Kerry被一些机器翻译系统翻译成了“爱尔兰的小母牛”,这是Kerry在英语中的另一个意思。)
那么如何正确地翻译这些词呢?人们很容易想到要用语法,分析语句,等等,其实,迄今为止,没有一种语法能够很好地解决这个问题,因为Bush不论翻译成人名还是灌木丛,都是名词,在语法上没有太大问题。当然爱较真的读者可能会提出,必须加一条规则“总统做宾语时,主语得是一个人”,要是这样,语法规则就多得数不清了,而且还有很多例外,比如一个国家在国际组织中也可以做主席(总统)的轮值国。其实,最简单却非常实用的方法是使用互信息。具体地解决方法大致如下:首先从大量文本中找出和总统布什一起出现的互信息最大的一些词,比如总统、美国、国会、华盛顿,等等,当然,再用同样的方法找出和灌木丛一起出现的互信息最大的词,比如土壤、职务、野生,等等。有了这两组词,在翻译Bush时,看看上下文中哪类相关的词多就可以了。这种方法最初由吉尔、丘奇和雅让斯基提出的。
相对熵
“相对熵”,在有些文献中它被称为“交叉熵”。相对熵也用来衡量相关性,但和变量的互信息不同,它用来衡量两个取值为正数的函数的相似性,它的定义如下:
\[KL(f(x) \mid \mid g(x))=\sum_{x \in X}f(x)*log \frac{f(x)}{g(x)}\]同样,大家不必关心公式本身,只要记住下面三条结论就好:
- 对于两个完全相同的函数,它们的相对熵等于零。
- 相对熵越大,两个函数差异越大;反之,相对熵越小,两个函数差异越小。
- 对于概率分布或者概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。
需要指出的是相对熵是不对称的,即:
\[KL(f(x)\mid \mid g(x)) \neq KL(g(x)\mid \mid f(x))\]这样使用起来有时不方便,为了让它对称,詹森和香农提出一种新的相对熵的计算方法,将上面的不等式两边取平均,即
\(JS(f(x) \mid \mid g(x)=\frac{1}{2}[KL(f(x)\mid \mid g(x))+KL(g(x) \mid \mid f(x))]\)
相对熵最早是用在信号处理上。如果两个随机信号,它们的相对熵越小,说明这两个信号越接近,否则信号的差异越大。后来研究信息处理的学者们也用它来衡量两段信息的相似程度,比如说如果一篇文章是照抄或改写另外一篇,那么这两篇文章中词频分布的相对熵就非常小,接近于零。
总结
信息熵正是对不确定性的衡量,因此可以想象信息熵能直接用于衡量统计语言模型的好坏。当然,有了上下文的条件,所以对高阶的语言模型,应该用条件熵。如果再考虑到从训练语料和真实应用的文本中得到的概率函数有偏差,就需要再引入相对熵的概念。
信息熵不仅是对信息的量化度量,而且是整个信息论的基础。它对于通信、数据压缩、自然语言处理都有很大的指导意义。