什么是主题模型
话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用。隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)是话题模型的典型代表,它可以将文档集中每篇文档的主题以概率分布的形式给出。通过分析一些文档,我们可以抽取出它们的主题(分布),根据主题(分布)进行主题聚类或文本分类。
我们先来了解一下话题模型中的几个概念:词(word)、文档(document)和主题(topic)。具体来说,”词”是待处理数据的基本单元,例如在文本处理任务中,一个词就是一个英文单词或有独立意义的中文词,“文档”是待处理的数据对象,它由一组词组成,这些词在文档中是不计顺序的,例如一篇论文、一个网页都可看作一个文档;这样的表示方式称为”词袋”(bag-of-words)。数据对象只要能用词袋描述,就可使用话题模型.”话题”表示一个概念,具体表示为一系列相关的词,以及它们在该概念下出现的概率。
形象地说,如下图所示,一个话题就像是一个箱子,里面装着在这个概念下出现概念较高的那些词。不妨假定数据集中一共包含K个话题和T篇文档,文档中的词来自一个包含N个词的词典。我们用$T$个$N$维向量$\omega={ \omega_!,\omega_2,···,\omega_T}$表示数据集(即文档集合),$K$个$N$维向量$\beta_k(k=1,2,3····,K)$表示话题,其中$\omega_t \in R^N $的第$n$个分量$\omega_{t,n}$表示文档$t$中词$n$的词频,$\beta_k \in R^N$的第$n$个分量$\beta_{k,n}$表示话题$k$中词$n$的词频。
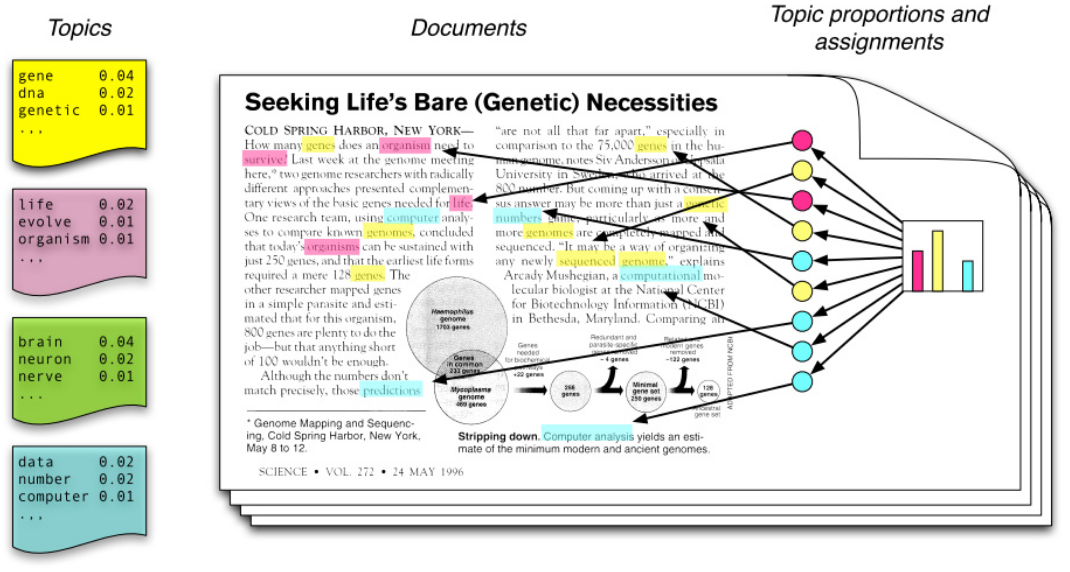
从左往右看,一个主题是由一些词语的分布定义的,比如蓝色主题是由2%的几率data,2%的number….构成的。一篇文章则是由一些主题构成的,比如右边的直方图。具体产生过程是,从主体集合中按概率分布选取一些主题,从该主题中按概率分布选取一些词语,这些词语构成了最终的文档(LDA模型中,词语的无序集合构成文档,也就是说词语的顺序没有关系)。
如果我们能将上述两个概率分布计算清楚,那么我们就得到了一个模型,该模型可以根据某篇文档推断出它的主题分布,即分类。由文档推断主题是文档生成过程的逆过程。
pLSA模型
在混合一元模型中,假定一篇文档只又一个主题生成,可实际中,一篇文章往往有多个主题,只是这多个主题各自在文档中出现的概率大小不一样。在$pLSA$中,假设文档由多个主题生成。下面通过一个投色子的游戏说明$pLSA $生成文档的过程。
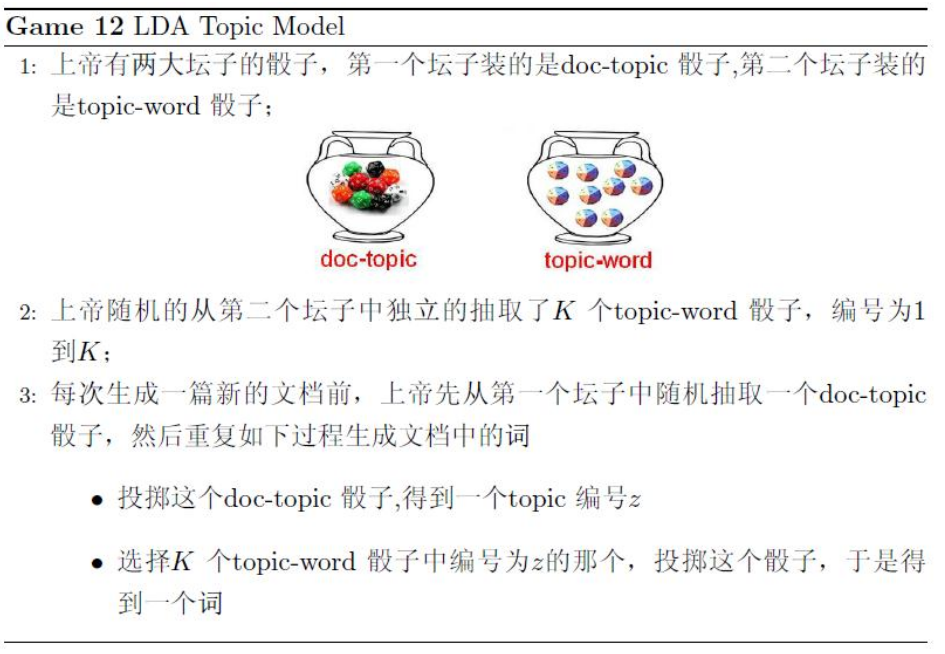
首先,假定你一共有$k$个可选的主题,有$v$个可选词。假设你每写一篇文档会制作一颗$K$面的’文档-主题 ‘骰子(扔词骰子能得到$k$个主题中的任意一个),和$k$个$v$面的’主题-词项’骰子(每个骰子对应一个主题,$k$歌骰子对应之前的$k$个主题,且骰子的每一面对应要选择的词项,$v$个面对应着$v$个可选的词)。比如$k=3$,即制作1个含有3个主题的”文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令$v=3$,制作3个有着3面的’主题-词项’骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
其次,每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。先扔“文档-主题”的骰子,假设以一定的概率得到的主题是:教育,所有下一步便是扔教育主题筛子,以一定的概率得到教育主题筛子对应的某个词大学。
-
上面这个投骰子产生词的过程简化一下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如可能选取教育主题的概率是0.5,选取经济主题的概率是0.3,选取交通主题的概率是0.2,那么这3个主题的概率分布便是$ {教育:0.5,经济:0.3,交通:0.2}$,我们把各个主题$z$在文档$d$出现的概率分布称之为主题分布,且是一个多项分布。
-
同样的,从主题分布中随机抽取出教育主题后,依然面对这3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如大学这个词被选中的概率是0.5,老师这个词被选中的概率是0.3,课程被选中的概率是0.2,那么这3个词的概率分布是${大学:0.5,老师:0.3,课程:0.2}$,我们把各个词$w$在主题$z$下的出现的概率分布称之为词分布,这个词分布也是一个多项分布。
-
所有,该主题和选词都是两个随机过程,先从主题分布${教育:0.5,经济:0.3,交通:0.2}$中抽取主题:教育,然后从该主题对应词分布${大学:0.5,老师:0.3,课程:0.2}$中抽取出词:大学。
最后,你不停的重复分”文档-主题”骰子和”主题-词项”骰子,重复$N$词(产生$N$个词),完成一篇文档,重复着产生一篇文档的方法$M$词,则完成$M$篇文档。
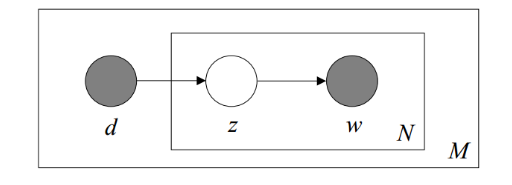
利用看到的文档推断其隐藏的主题(分布)的过程,就是主题建模的目的:自动地发现文档集中的主题(分布)。文档d和单词w是可被观察到的,但主题z却是隐藏的。如下图所示(图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档)。
上图中,文档d和词w是我们得到的样本,可观测得到,所有对于任意一篇文档,其$P(w_j\mid d_{i})$是已知的。根据这个概率可以训练得到文档-主题概率以及主题-词频概率。即:
故得到文档中每个词的生成概率为:
\[P(w_j,d_i)=P(d_i)P(w_j \mid d_i)=P(d_i)\sum^K_{k=1}P(w_j \mid z_k)P(z_k \mid d_i)\]$P(d_i)$可以直接得出,而$P(z_{k} \mid d_i)$和$P(w_j \mid z_k$未知,所以$\theta=(P(z_k\mid d_i),P(w_j \mid z_k))$就是我们要估计的参数,我们要最大化这个参数。因为该待估计的参数中含有隐变量z,所以我们可以用EM算法来估计这个参数。
文档生成
LDA的不同之处在于,pLSA的主题的概率分布P(c|d)是一个确定的概率分布,也就是虽然主题c不确定,但是c符合的概率分布是确定的,比如符合某个多项分布,这个多项分布的各参数是确定的。 但是在LDA中,这个多项分布都是不确定的,高斯分布又服从一个狄利克雷先验分布(Dirichlet prior)。即LDA就是pLSA的贝叶斯版本,正因为LDA被贝叶斯化了,所以才会加的两个先验参数。
在《LDA数学八卦》一文中,对文档的生成过程有个很形象的描述:
在现实任务中可通过统计文档中出现的词来获得词频向量$\omega_i(i=1,2,····,T)$,但通常并不知道这组文档谈论了哪些话题,也不知道每篇文档与哪些话题有关,LDA从生成式模型的角度来看待文档和话题,具体来说,LDA认为每篇文档包含多个话题,不妨用向量$\theta_t \in R^K$表示文档$t$中所包含的每个话题的比例,$\theta_{t,k}$即表示文档$t$中包含话题$k$的比例,进而通过下面的步骤有话题生成文档$t$:
- 根据参数$\alpha$的狄利克雷分布随机采样一个话题分布$\theta_t$;
- 按如下步骤生成文档中的$N$个词:
- 根据$\theta_t$进行话题指派,得到文档$t$中词$n$的话题$z_t,n$;
- 根据指派的话题所对应的词频分布$\beta_k$随机采用生成词
第一张图演示出根据以上步骤生成文档的过程。显然,这样生成的文档自然地以不同比例包含多个话题(步骤1),文档中每个词来自一个话题(步骤2-1),而这个话题是依据话题比例产生的(步骤2-2)。
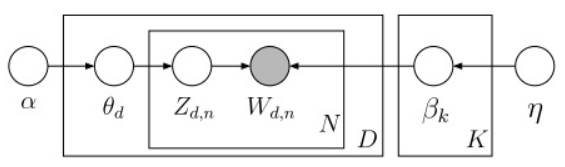
下图描述了LDA的变量关系,其中文档中的词频$\omega_{t,n}$是唯一的已观测变量,它依赖于对这个词进行的话题指派$z_{t,n}$,以及话题所对应的词频$\beta_k$;同时,话题指派$z_{t,n}$依赖于话题分布$\theta_t,\theta_t$依赖于狄利克雷分布的参数$\alpha$,而话题词频则依赖于参数$\eta$。
于是LDA的生成过程对应的观测变量和隐藏变量的联合分布如下:
\[p(\beta_{1:K},\theta_{1:D},z_{1:D},w_{1:D})=\prod_{i=1}^Kp(\beta)\prod_{d=1}^Dp(\theta_d)\Bigg(\prod_{n=1}^Np(z_{d,n}\mid\theta_d)p(w_{d,n}\mid\beta_{1:K},z_{d,n})\Bigg)\]式子有点长,耐心地从左往右看:
式子的基本符号约--$\beta$表示主题,$\theta$表示主题的概率,$z$表示特定文档或词语的主题,$w$为词语。进一步说--
$\beta_{1:k}$为全体主题集合,其中$\beta_k$是第k个主题的词的分布(如上图1左部所示)。第$d$个文档中该主题所占的比例为$\theta_d$,其中$\theta_{d,k}$表示第$k$个主题在第$d$个文档中的比例(图1右部的直方图)。第$d$个文档的主题全体为$z_d$,其中$z_{d,n}$是第$d$个文档中第$n$个词的主题(如上图1中有颜色的圆圈)。第$d$个文档中所有词记为$w_d$,其中$w_{d,n}$是第$d$个文档中第$n$个词,每个词都是固定的词汇表中的元素。
$p(\beta)$表示从主题集合中选取了一个特定主题,$p(\theta_d)$表示该主题在特定文档中的概率,大括号的前半部分是该主题确定时该文档第$n$个词的主题,后半部分是该文档第$n$个词的主题与该词的联合分布。连乘号描述了随机变量的依赖性,概率图描述如上图所示。
比如,先选取了主题,才能从主题里选词。具体来说,一个词受两个随机变量的影响(直接或间接),一个使确定了主题后文档中该主题的分布$\theta_d$,另一种是第$k$个主题的词的分布$\beta_k$(也就是第二张图中的第2个坛子)。