本文参照博客《GBDT算法原理深入解析》,部分内容略微修改
GBDT算法:原理篇
GBDT是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎。这里简单介绍下GBDT算法的原理。
梯度提升(Gradient boosting)是一种用于回归、分类和排序任务的机器学习技术,属于Boosting算法族的一部分。Boosting是一族可将弱学习器提升为强学习器的算法,属于集成学习(ensemble learning)的范畴。Boosting方法基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断要好。通俗地说,就是“三个臭皮匠顶个诸葛亮”的道理。梯度提升同其他boosting方法一样,通过集成多个弱学习器,通常是决策树,来构建最终的预测模型。
Boosting、Bagging和Stacking是集成学习的三种主要方法。不同于bagging方法,boosting方法通过分布迭代(stage-wise)的方式来构建模型,在迭代的每一步构建的弱学习器都是为了弥补已有模型的不足。Boosting族算法的著名代表是AdaBoost,AdaBoost算法通过给已有模型预测错误的样本更高的权重,使得先前的学习器做错的训练样本在后续受到更多的关注的方式来弥补已有模型的不足。与AdaBoost算法不同,梯度提升方法在迭代的每一步构建一个能够沿着梯度最陡的方向降低损失的学习器来弥补已有模型的不足。经典的AdaBoost算法只能处理采用指数损失函数的二分类学习任务,而梯度提升方法设置不同的可微损失函数可以处理各类学习任务(多分类、回归、Ranking等),应用范围大大扩展。另一方面,AdaBoost算法对异常点(outlier)比较敏感,而梯度提升算法通过引入bagging思想、加入正则项等方法能够有效抵御训练数据中的噪音,具有更好的健壮性。这也是为什么梯度提升算法(尤其是采用决策树作为弱学习器的GBDT算法)如此流行的原因。
基于梯度提升算法的学习器叫做GBM(Gradient Boosting Machine)。理论上,GNM可以选择各种不同的学习算法作为基学习器。GBDT实际上是GBM的一种情况。
为什么梯度提升方法倾向于选择决策树作为基学习器呢?(也就是GB为什么要和DT结合,形成GBDT)决策树可以认为是if-then规则的集合,易于理解,可解释性强,预测速度快。同时,决策树算法相比于其他的算法需要更少的特征工程,比如不用做特征标准化,可以很好的处理字段缺失的数据,也可以不用关心特征间是否相互依赖等。决策树能够自动组合多个特征。
不过,单独使用决策树算法,又容易过拟合缺点。所幸的是,通过各种方法,抑制决策树的复杂性,降低单棵决策树的拟合能力,再通过梯度提升的方法集成多个决策树,最终能够很好的解决过拟合的问题。由此可见,梯度提升方法和决策树学习算法可以互相取长补短,是一对完美的搭档。
至于抑制单棵决策树的复杂度的方法有很多,比如限制树的最大深度、限制叶子节点的最少样本数量、限制节点分裂时的最少样本数量、吸收Bagging的思想对训练样本采样(subsample),在学习单棵决策树只使用一部分训练样本、借鉴随机森林的思路在学习单棵决策树时只采样一部分特征、在目标函数中添加正则项惩罚辅助的树结构等。
举个例子
考虑一个简单的例子来演示GBDT算法原理。
下面是一个二分类问题,1表示可以考虑的相亲对象,0表示不考虑的相亲对象。
特征维度有3个维度,分别对象、身高、颜值
| id | Lable | hight | money | face |
|---|---|---|---|---|
| 0 | 1 | 20 | 80 | 100 |
| 1 | 1 | 60 | 90 | 25 |
| 2 | 1 | 3 | 95 | 95 |
| 3 | 1 | 66 | 95 | 60 |
| 4 | 0 | 30 | 95 | 25 |
| 5 | 0 | 20 | 12 | 55 |
| 6 | 0 | 15 | 14 | 99 |
| 7 | 0 | 10 | 99 | 2 |
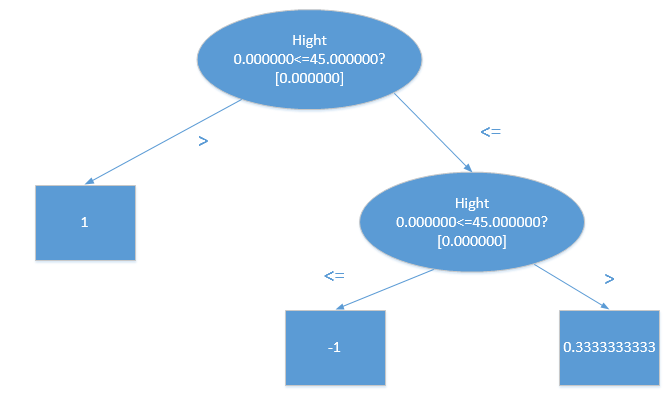
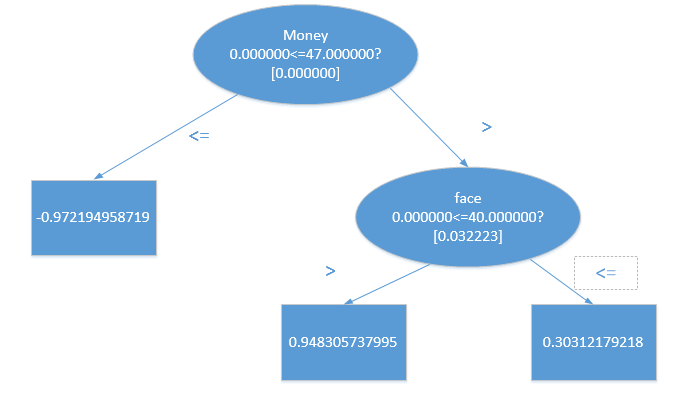
对应这个例子,训练结果是perfect的,全部正确,特征权重可以看出,对应这个例子可以训练结果颜值的重要度最大,看一下训练得到的树。
Tree 0:
Tree 1
原理推导
目标函数
监督学习的关键概念:模型(model)、参数(parameters)、目标函数(objective function)模型就是所要学习的条件概率分布或者决策函数,它决定了在给定特征向量时如何预测出目标。
参数就是我们要从数据中学习得到的内容。模型通常是由一个参数向量决定的函数。
目标函数通常定义为如下形式:
\[obj(\theta)=L(\theta)+\Omega(\theta)\]其中,$L$是损失函数,用来衡量模型拟合训练数据的好坏程度;$\Omega$称之为正则项,用来衡量学习到的模型复杂度。
目标函数之所以定义为损失函数和正则项两部分,是为了尽可能平衡模型的偏差和方差(Bias Variance Trade-off)。最小化目标函数意味着同时最小化损失函数和正则项,损失函数最小化表明模型能够较好的拟合训练数据,一般也预示着模型能够较好地拟合真实数据(groud true);另一方面,对正则项的优化鼓励算法学习到较简单的模型,简单模型一般在测试样本上的预测结果比较稳定、方差较小(奥坎姆剃刀原则)。也就是说,优化损失函数尽量使模型走出欠拟合的状态,优化正则项尽量使模型避免过拟合
加法模型
GBDT算法可以看做是由K棵数组成的加法模型:
\[\hat{y}_i=\sum_{k=1}^K f_k(x_i), f_k \in F \tag 0\]其中F为所有树组成的函数空间,以回归任务为例,回归树可以看作为一个把特征向量映射为某个score的函数。该模型的参数为$\Theta={f_1,f_2, \cdots, f_K }$。于一般的机器学习算法不同的是,加法模型不是学习d维空间中的权重,而是直接学习函数(决策树)集合。
上述加法模型的目标函数定义为:$Obj=∑ni=1l(yi,y^i)+∑Kk=1Ω(fk)Obj=∑i=1nl(yi,y^i)+∑k=1KΩ(fk)$,其中$Ω$表示决策树的复杂度,那么该如何定义树的复杂度呢?比如,可以考虑树的节点数量、树的深度或者叶子节点所对应的分数的L2范数等等。
如何来学习加法模型呢?
解决这一优化问题,可以使用前向分布算法(forward stagewise algorithm)。因为学习的是加法模型,如果能够从前往后,每一步只学习一个基函数及其系数(结构),逐步逼近优化目标函数,那么就可以简化复杂度。这一学习过程称为Boosting。具体地,我们从一个常量预测开始,每次学习到一个新的函数,过程如下:
\[\begin{split} \hat{y}_i^0&=0\\ \hat{y}_i^1 &= f_1(x_i) = \hat{y}_i^0 + f_1(x_i) \\\hat{y}_i^2 &= f_1(x_i) + f_2(x_i) = \hat{y}_i^1 + f_2(x_i) \\& \cdots \\\hat{y}_i^t &= \sum_{k=1}^t f_k(x_i) = \hat{y}_i^{t-1} + f_t(x_i) \\\end{split}\]那么,在每一步如何决定哪一个函数$f$被加入呢?指导原则还是最小化目标函数。
在第$t$步,模型对$x_i$的预测为$\hat{y}^t=\hat{y}^{t-1}+f_t(x_i)$,其中$f_t(x_i)$为这一轮我们要学习的函数(决策树)。这个时候目标函数可以写为:
\[\begin{split}Obj^{(t)} &= \sum_{i=1}^nl(y_i, \hat{y}_i^t) + \sum_{i=i}^t \Omega(f_i) \\&= \sum_{i=1}^n l\left(y_i, \hat{y}_i^{t-1} + f_t(x_i) \right) + \Omega(f_t) + constant\end{split}\tag{1}\]举例说明,假设损失函数为平方损失(square loss),则目标函数为:
\[\begin{split}Obj^{(t)} &= \sum_{i=1}^n \left(y_i - (\hat{y}_i^{t-1} + f_t(x_i)) \right)^2 + \Omega(f_t) + constant \\&= \sum_{i=1}^n \left[2(\hat{y}_i^{t-1} - y_i)f_t(x_i) + f_t(x_i)^2 \right] + \Omega(f_t) + constant\end{split}\tag{2}\]其中,$(\hat{y_i}^{t-1}-y_i)$称之为残差(residual)。因此,使用平方损失函数时,GBDT算法的每一步在生成决策树时只需要拟合前面的模型的残差。
泰勒公式:设nn是一个正整数,如果定义在一个包含a的区间上的函数$f$在a点处n+1次可导,那么对于这个区间上的任意x都有:$\displaystyle f(x)=\sum {n=0}^{N}\frac{f^{(n)}(a)}{n!}(x-a)^ n+R n(x)$,其中的多项式称为函数在a处的泰勒展开式,$R_n(x)$是泰勒公式的余项且是$(x−a)^n$的高阶无穷小。
—-维基百科
根据泰勒公式把函数$f(x+\Delta x)$在点$x$处二阶展开,可得到如下等式:
\[f(x+\Delta x) \approx f(x) + f'(x)\Delta x + \frac12 f''(x)\Delta x^2 \tag 3\]由等式(1)可知,目标函数是关于变量$\hat{y_i}^{t-1}+f_t(x_i)$的函数,若把变量$\hat{y}_i^{t-1}$看出等式(3)中的$x$,把变量$f_t(x_i)$看成是等式(3)中的$\Delta x$,则等式(1)可转化为:
\[Obj^{(t)} = \sum_{i=1}^n \left[ l(y_i, \hat{y}_i^{t-1}) + g_if_t(x_i) + \frac12h_if_t^2(x_i) \right] + \Omega(f_t) + constant \tag 4\]其中,$g_i$定义为损失函数的一阶导数,即$g_i=\partial_{\hat{y}^{t-1}}l(y_i,\hat{y}^{t-1})$;$h_i$定义为损失函数的二阶导数,即$h_i=\partial_{\hat{y}^{t-1}}^2l(y_i,\hat{y}^{t-1})$。
假设损失函数为平方损失函数,则$g_i=\partial_{\hat{y}^{t-1}}(\hat{y}^{t-1} - y_i)^2 = 2(\hat{y}^{t-1} - y_i)$,$h_i=\partial_{\hat{y}^{t-1}}^2(\hat{y}^{t-1} - y_i)^2 = 2$,把$g_i$和$h_i$代入等式(4)即等式(2)。
由于函数中的常量在函数最小化的过程中不起作用,因此我们可以从等式(4)中移除掉常量项,得:
$Obj^{(t)} \approx \sum_{i=1}^n \left[ g_if_t(x_i) + \frac12h_if_t^2(x_i) \right] + \Omega(f_t) \tag 5$
由于要学习的函数仅仅依赖于目标函数,从等式(5)可以看出只需为学习任务定义好损失函数,并为每个训练样本计算出损失函数的一阶导数和二阶导数,通过在训练样本集上最小化等式(5)即可求得每步要学习的函数$f(x)$,从而根据加法模型等式(0)可得最终要学习的模型。
GBDT算法
一棵生成好的决策树,假设其叶子节点个数为$T$,该决策树是由所有叶子节点对应的值组成的向量$w \in R^T$,以及一个把特征向量映射到叶子节点索引的函数$q:R^d \to {1,2,\cdots,T}$.因此,决策树可以定义为$f_t(x)=w_q(x)$。
决策树的复杂度可以由正则项$\Omega(f_t)=\gamma T + \frac12 \lambda \sum_{j=1}^T w_j^2$来定义,即决策树模型的复杂度由生成的子节点数量和叶子节点对应的值向量的L2范数决定。
定义集合$I_j={ i \vert q(x_i)=j }$为所有被划分到叶子节点$j$的训练样本的集合。等式(5)可以根据树的叶子节点重新组织为T个独立的二次函数的和:
\[\begin{split}Obj^{(t)} &\approx \sum_{i=1}^n \left[ g_if_t(x_i) + \frac12h_if_t^2(x_i) \right] + \Omega(f_t) \\ &= \sum_{i=1}^n \left[ g_iw_{q(x_i)} + \frac12h_iw_{q(x_i)}^2 \right] + \gamma T + \frac12 \lambda \sum_{j=1}^T w_j^2 \\ &= \sum_{j=1}^T \left[(\sum_{i \in I_j}g_i)w_j + \frac12(\sum_{i \in I_j}h_i + \lambda)w_j^2 \right] + \gamma T\end{split}\tag 6\]定义$G_j=\sum_{i \in I_j}g_i$,$H_j=\sum_{i \in I_j}h_i$,则等式(6)可写为:
$Obj^{(t)} = \sum_{j=1}^T \left[G_iw_j + \frac12(H_i + \lambda)w_j^2 \right] + \gamma T$
假设树的结构是固定的,即函数$q(x)$确定,令函数$Obj^{(t)}$的一阶导数等于0,即可求得叶子节点$j$对应的值为:
\[w_j^*=-\frac{G_j}{H_j+\lambda} \tag 7\]此时,目标函数值为:
\[Obj = -\frac12 \sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T \tag 8\]综上,为了便于理解,单棵决策树的学习过程可以大致描述为:
1.枚举所有可能的树结构q
2.用等式(8)为每个q计算其对应的分数$Obj$,分数越小说明对应的树结构越好
3.根据上一步的结果,找到最佳的树结构,用等式(7)为树的每个叶子节点计算预测值
然而,可能的树结构数量是无穷的,所有实际上我们不可能枚举所有可能的树结构。通常情况下,我们采用贪心策略来生成决策树的每个节点。
1.从深度为0的树开始,对每个叶节点枚举所有的可用特征。
2.针对每个特征,把属于该节点的训练样本根据该特征值升序排序,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的最大收益(采用最佳分裂的收益)。
3.选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,把该节点生长出左右两个新的叶节点,并为每个新节点关联对应的样本集。
4.回到第1步,递归执行到满足特定条件为止。
如何计算每次分裂的收益呢?假设当前节点记为$C$,分裂之后左孩子节点记为$L$,右孩子节点记为$R$,则该分裂获得的收益定义为当前节点的目标函数值减去左右两个孩子节点的目标函数值之和:$Gain=Obj_C−Obj_L−Obj_R,$具体地,根据等式(8)可得:
$Gain=\frac12 \left[ \frac{G_L^2}{H_L+\lambda} + \frac{G_R^2}{H_R+\lambda} - \frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma$
其中,$−γ$项表示因为增加了树的复杂性(该分裂增加了一个叶子节点)带来的惩罚
最后,总结一下GBDT的学习算法:
1.算法每次迭代生成一棵新的决策树
2.在每次迭代开始之前,计算损失函数在每个训练样本点一阶导数$g_i$和二阶导数$h_i$
3.把贪心策略生成新的决策树,通过等式(7)计算每个叶节点对应的预测值
4.把新生成的决策树$f_t(x)$添加到模型中:$\hat{y}_i^t = \hat{y}_i^{t-1} + f_t(x_i)$
通常在第四步,我们把模型更新公式替换为:$\hat{y}_i^t = \hat{y}_i^{t-1} + \epsilon f_t(x_i)$,其中$\epsilon$称之为步长或者学习速率。增加$\epsilon$因子的目的是为了避免模型过拟合。
Xgboost 和 GBDT 的区别:
GBDT:
- GBDT 它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
- GBDT 的缺点也很明显,Boost 是一个串行过程,不好并行化,而且计算复杂度高,同时不太适合高维稀疏特征;
- 传统 GBDT 在优化时只用到一阶导数信息。
Xgboost:
它有以下几个优良的特性:
- 显示的把树模型复杂度作为正则项加到优化目标中。
- 公式推导中用到了二阶导数,用了二阶泰勒展开。(GBDT 用牛顿法貌似也是二阶信息)
- 实现了分裂点寻找近似算法。
- 利用了特征的稀疏性。
- 数据事先排序并且以 block 形式存储,有利于并行计算。
- 基于分布式通信框架 rabit,可以运行在 MPI 和 yarn 上。(最新已经不基于 rabit 了)。
- 实现做了面向体系结构的优化,针对 cache 和内存做了性能优化。