本文摘自文章《到底什么是生成式对抗网络GAN?》,部分内容稍作修改。
首先,先介绍一下生成模型(generative model),它在机器学习的历史上一直占有举足轻重的地位。当我们拥有大量的数据,例如图像、语音、文本等,如果生成模型可以帮助我们模拟这些高维数据的分布,那么对很多应用将大有裨益。
针对数据量缺乏的场景,生成模型则可以帮助生成数据,提高数据数量,从而利用半监督学习提升学习效率。语言模型(language model)是生成模型被广泛使用的例子之一,通过合理建模,语言模型不仅可以帮助生成语言通顺的句子,还在机器翻译、聊天对话等研究领域有着广泛的辅助应用。
那么,如果有数据集$S={x1,..xn}$,如何建立一个关于这个类型数据的生成模型呢?最简单的方法就是:假设这些数据的分布$P${X}服从$g(x;\theta)$,在观测数据上通过最大化似然函数$\theta$的值,即最大似然法:
$max_{\theta}\sum_{i=1}^nlogg(x_i;\theta)$
工作原理
以图像模型举例,假设我们有一个图片生成模型(generator),它的目标是生成一张真实的图片。与此同时我们有一个图像判别模型(discriminator),它的目标是能够正确判别一张图片是生成出来的还是真实存在的。那么如果我们把刚才的场景映射成图片生成模型和判别模型之间的博弈,就变成了如下模式:生成模型生成一些图片->判别模型学习区分生成的图片和真是图片->生成模型根据判别模型改进自己,生成新的图片->…
这个场景直至生成模型与判别模型无法提高自己———即判别模型无法判断一张图片是生成出来的还是真实的而结束,此时生成模型就会成为一个完美的模型。这种相互学习的过程听起来是不是很有趣?
上述这种博弈式的训练过程,如果采用神经网络作为模型类型,则被称为生成式对抗网络(GAN)。用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是$g(z)$,其中$z$是一个随机噪声,而$g$将这个随机噪声转化为数据类型$x$,仍拿图片问题举例,这里$g$的输出就是一张图片。$D$是一个判别模型,对任何输入$x$,$D(x)$的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令Pr和Pg分别代表真实图像的分布与生成图像的分布,我们判别模型的目标函数如下: \(max_{D}E_{x~P_r}[log_D(x)]+E_{x~P_g}[log(1-D(x))]\)
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,那么整个的优化目标函数如下:
\[min_gmax_DE_{x~-P_r}[logD(x)]+E_{x~p_g}[log(1-D(x))]\]这个最大最小化目标函数如何进行优化呢?最直观的处理办法就是分别对$D$和$g$进行交互迭代,固定$g$,优化$D$,一段时间后,固定$D$再优化$g$,直到过程收敛。
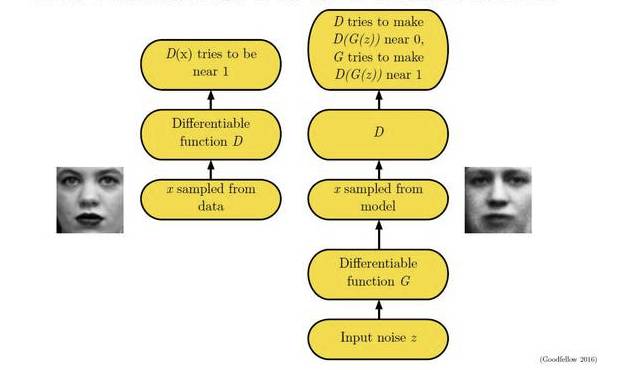
一个简单的例子如下图所示:假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好的区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片与真实图片分布更加接近,这样的迭代不断进行,直至最终收敛,生成分布和真实分布重合。
GAN在图像中的应用—DCGAN
为了方便大家更好地理解生成式对抗网络的工作过程,下面介绍一个GAN的使用场景—在图片中的生成模型DCGAN。
在图像生成过程中,如何设计生成模型和判别模型呢?深度学习里,对图像分类建模,刻画图像不同层次,抽象信息表达的最有效的模型是:CNN(convolutional neural network,,卷积神经网络)。
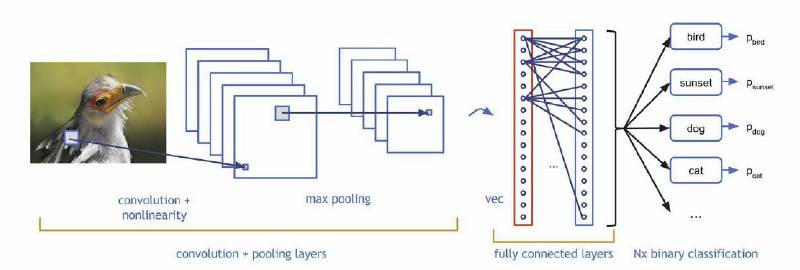
CNN是深度神经网络的一种,可以通过卷积层提取不同层级的信息,如上图所示。CNN模型以图片作为输入,以图片、类别抽象表达作为输出,如:纹理、形状等等,其实这与人类对图像的认知有相似之处,即:我们对一张照片的理解也是多层次逐渐深入的。
那么生成图像的模型是什么样子的呢?想想小时候上美术课,我们会先考虑构图,再勾画轮廓,然后再画细节,最后填充颜色,这事实上也是一个多层级的过程,就像是把图像理解的过程反过来,于是,人们为图像生成设计了一种类似反卷积的结够:Deep convolutional NN for GAN (DCGAN)。
DCGAN采用一个随机噪声向量作为输入,如高斯噪声。输入通过与CNN类似但是相反的结构,将输入放大成二维数据。通过采用这种结构的生成模型和CNN结构的判别模型,DCGAN在图片生成上可以达到相当可观的效果。
GAN在半监督学习中的应用
再来看一个GAN在半监督学习(semi supervised learning)中的例子。假如我们面对一个多分类的任务,手里只有很少的标注样本,同时有很多没有标注的样本,怎么能够利用GAN的思路合理使用无标签数据,提高分类性能呢?
在去年NIPS大会上,来自OpenAI的作者提供了如下思路:考虑一个$k$分类任务,有一个判别模型$G$可以帮助生成样本,与此同时,有一个判别模型做一个$k+1$分类任务,其中新加的类是预测样本是否是由生成模型生成的。跟传统GAN不同,这里我们最终需要的是判别模型,而不是生成模型。
简单而言,目标函数针对不同数据,可以分为两部分。对于有标注的样本,目标是希望判别模型能够正确输出标签。而对于没有标注的生成样本,则是由GAN定义的loss。
该作者认为这样处理的好处是可以充分利用未标注数据来学习样本分布,从而辅助监督学习的训练过程。实验结果也显示通过这种处理方法训练出来的判别模型,在合理利用未标注数据方面,有着比其他方法更好的效果。
GAN for NLP
Adversial Training算是GAN的源头,而GAN算是其在生成器领域的一大成就。但这个GAN在文本领域一直不怎么work。GAN的作者早在原版论文时就提及,GAN只适用于连续型数据的生成,对于离散型数据效果不佳(使得一时风头无两的GAN在NLP领域一直无法超越生成模型的另一大佬VAE)。文本数据就是最典型的一种离散型数据,这里所谓的离散,并不是指:文本由一个词一个词组成。离散型数据的真正含义,我们要从连续性数据说起。图像数据就是典型的连续性数据,故而GAN能够直接生成出逼真的画面来。
图像数据在计算机中均被表示为矩阵,若是黑白图像矩阵中元素的值记为像素值或者灰度值,就算是彩色图像,图像张量即被多加了一阶用于表示RGB通道,图像矩阵中的元素是可微分的,其数值直接反映出图像本身的明暗,色彩等因素,很多这样的像素点组合在一起,就形成了图像,也就是说,从图像矩阵到图像,不需要“采样”(Sampling)。
我们通过论文《Adversarial Training Methods for Semi-Supervised Text Classification 》来谈谈关于对抗训练在自然语言处理领域应用的一些想法。
这篇文章的核心思想:通过Goodfellow提出的Fast Gradient Sign Method(FGSM)来计算扰动,添加到连续的Word Embedding上产生X_adv,再一次送入到模型中,得到Adverarial Loss,通过和原来的Classification Loss(Cross-entropy)做一个相加得到新的Loss,通过优化这个Loss,能够在文本分类任务上取得超过目前State-of-art的表现。
Perturbation on Word Embedding
在之前部分也提到,和图像领域不同,组成文本的词语一般都是以one-hot vector 或者是Word index vector来表示的,可以视作离散的,而非连续的RGB值。这就导致如果我们直接在raw text上进行扰动,则可能扰动的方向和大小都没有任何明确的语义对应。
文章提到,这种Adversarial Training和图像中有所不同,其通过FGSM产生的X_adv并不能是做一种对抗样本,因为扰动之后的Word Embedding有极大可能并不能映射到一个真实存在的词语上,这和图像中RGB的扰动能够产生人眼无法分辨区别的对抗样本是不一样的。所以作者认为,这种Adversarial Training更类似于一种Regularization的手段,能够使得word embedding的质量更好,避免overfitting,从而取得出色的表现。
Adversarial Training能提升Word Embedding质量的一个原因是:
有些词语比如(good和bad),其在语句中Grammatical Role是最相近的,我理解为词形相同(都是形容词),并且周围一并出现的词语也是相近的,比如我们经常用修饰天气或者一天的情况(The weather is good/bad;It’s a good/bad day),这些词的Word Embedding距离也是非常相近的。
我们可以猜测,在word embedding上添加的Perurbation很可能导致原来的good变成bad,导致分类错误,计算的Adversarial Loss很大,而计算Adversarial Loss的部分是不参与梯度计算的,也就是说,模型(LSTM和最后的Dense Layer)的Weight和Bias的改变并不会影响Adversarial Loss,模型只能通过改变Word Embedding Weight来努力降低它。进而如文中所说:
Adversarial training ensures that the meaning of a sentence cannot be inverted via a small change, so these words with similar grammatical role but different meaning become separated.
含义不同而语言结构角色类似的词能够通过这种Adversarial Training的方法而被分离开,从而提升了Word Embedding的质量,帮助模型取得了非常好的效果。
Why Adversarial Training
接下来谈谈在NLP领域中Adversarial Training是一个什么样的角色,或者说我们希望它们起到什么样的效果?
我任务,主要有以下四种主要的目的:
1.作为Regularization 的手段,提升模型的性能(分类准确率),防止过拟合
2.产生对抗样本,攻击深度学习模型,产生错误结果(错误分类)
3.让上述的对抗样本参与的训练过程,提升对对抗样本的防御能力,具有更好的泛化能力
4.利用GAN来进行自然语言的生成。
第四点并不在这篇文章的讨论范围内,而前三点事实上可以认为是两种不同的手段,而它们看似都是对模型泛化能力的提升,但其对于泛化标的是有所区别的,前者是通过提升 Word Embedding 质量,可以认为具有一定的普适性;而后者,则主要是对于对抗样本的适应和泛化。
本文摘自文章《到底什么是生成式对抗网络GAN?》,部分内容稍作修改。