在很早的一篇博文中在Keras模型中使用预训练的词向量,我们介绍了如何使用Keras实现一个卷积神经网络的文本分类模型。基于CNN的文本分类模型简直是新手学习一个深度学习框架的绝佳练手项目,所以,这篇博文我们将介绍一个基于tensorflow的卷积神经网络的文本分类模型,记录一下自己在学习tensorflow时候的爬坑过程。
模型简介
模型架构如图所示:
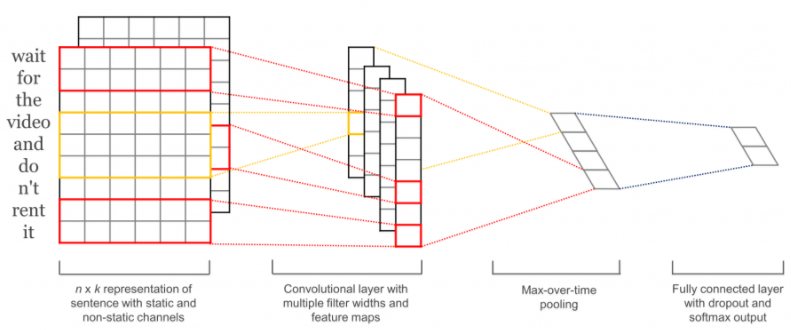
从左向右看,第一层是词嵌入层,主要将输入文本词映射到一个低维空间中;第二层是卷积层,通过不同宽度的卷积核在词矩阵上进行卷积操作,,例如卷积核的大小为3,4,5,以此捕获n-gram语义信息;第三层是池化层,我们对卷积后的向量进行最大池化操作并将向量拼接在一起,捕获句子中最明显的特征;最后,我们将向量送入全连接层中,进行最终的分类。
我们的模型大致就是按照上述架构进行搭建的,使用预训练的词向量(glove.6B.100),你也可以使用其它流行的预训练词向量,如elmo或者基于BERT的预训练词向量。
卷积神经网络的文本分类模型是基于tensorflow实现的,主要分下三个部分:数据预处理,模型模块,训练模块。
数据预处理
$\color{red}{炼丹的道路千万条,数据预处理第一条}$。我们首先来看如何对数据进行处理
第一步是加载数据,加载完数据,我们对数据进行构建一个字典,为后续处理提供基础:
def char_mapping(sentences,lower):
#获取词的列表
chars = [[x.lower() if lower() else x for x in s.split()] for s in sentence]
dico = cretae_dico(chars)
char_to_id, id_to_char = create_mapping(dico)
print("Found %i unique words (%i in total)" %(len(dico),sum(len(x) for x in chats)
在词典和预训练词向量之间建立起映射,获得预训练的词向量矩阵:
def load_word2vec(emb_path, id_to_word, word_dim):
"""
Load word embedding from pre-trained file
embedding size must match
"""
new_weights = np.zeors(len(id_to_word),word_dim)
print('Loading pretrained embeddings from {}...'.format(emb_path))
pre_trained = {}
emb_invalid = 0
for i, line in enumerate(codecs.open(emb_path, 'r', 'utf-8')):
line = line.rstrip().split()
if len(line) == word_dim + 1:
pre_trained[line[0]] = np.array(
[float(x) for x in line[1:]]
).astype(np.float32)
else:
emb_invalid += 1
if emb_invalid > 0:
print('WARNING: %i invalid lines' % emb_invalid)
c_found = 0
c_lower = 0
c_zeros = 0
n_words = len(id_to_word)
# Lookup table initialization
for i in range(n_words):
word = id_to_word[i]
if(i==0):
new_wwights[i+1] = np.random.uniform(-0.25,0.25,word_dim)
if word in pre_trained:
new_weights[i] = pre_trained[word]
c_found += 1
elif word.lower() in pre_trained:
new_weights[i] = pre_trained[word.lower()]
c_lower += 1
elif re.sub('\d', '0', word.lower()) in pre_trained: #replace numbers to zero
new_weights[i] = pre_trained[
re.sub('\d', '0', word.lower())
]
c_zeros += 1
print('Loaded %i pretrained embeddings.' % len(pre_trained))
print('%i / %i (%.4f%%) words have been initialized with '
'pretrained embeddings.' % (
c_found + c_lower + c_zeros, n_words,
100. * (c_found + c_lower + c_zeros) / n_words)
)
print('%i found directly, %i after lowercasing, '
'%i after lowercasing + zero.' % (
c_found, c_lower, c_zeros
))
return new_weights
然后是文本数据映射成id、数据补齐以及迭代生成批次数据送入到模型中:
def pad_data(data,length):
chars = []
max_length = length
for line in data:
if(len(line)<max_length):
padding = [0]*(max_length-len(line))
chars.append(line+padding)
else:
chars.append(line[0:length])
return chars
def batch_iter(data, batch_size, num_epochs, shuffle=True):
"""
生成一个批次的数据.
"""
data = np.array(data)
data_size = len(data)
num_batches_per_epoch = int((len(data)-1)/batch_size) + 1
for epoch in range(num_epochs):
# 将每一轮的数据打乱
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_indices]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
yield shuffled_data[start_index:end_index]
模型搭建
class TextCNN(object):
"""
文本分类模型
词嵌入层,卷积层,池化层,分类层
"""
def __init__(
self, embeddings,sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# 占位符,输入,输出,dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# 词向量层 随机初始化
'''
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
'''
#使用预训练的词向量
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
shape = [vocab_size, embedding_size],
initializer = tf.constant_initializer(embeddings),
name="W")
#查表
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
pooled_outputs = []
for kernel_size in filter_sizes:
with.tf.variable_scope("CNN-max-pooling-%s" % kernel_size):
conv = tf.layer.conv1d(self.embedd_chars,num_filters,kernel_size,name='conv')
gmp = tf.reduce_max(conv,reduction_indices=[1],name='gmp')
pooled_outputs.append(gmp)
self.h_pool = tf.concat(pooled_outputs,1)
num_total_filters = len(filter_size)*num_filters
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(self.h_pool, num_total_filters, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
在模型搭建过程中,文本经过词嵌入层获得每个词的embedding维度,即[bacth_size,seq_length,embedding_dim],如果要想像图像一样在两个维度上进行卷积操作,我们需要对维度进行转换,即再增加一维。这里,我们只使用一维卷积,然后使用最大池化,获取全局最大的特征。
模型训练
# Parameters
# ==================================================
def preprocess():
# Data Preparation
# ==================================================
‘’‘
# Load data
print("Loading data...")
x_text, y = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
def train(x_train, y_train, vocab_processor, x_dev, y_dev,pre_weights):
# 训练
# ==================================================
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
cnn = TextCNN(
embeddings = pre_weights,
sequence_length=x_train.shape[1],
num_classes=y_train.shape[1],
vocab_size=len(vocab_processor.vocabulary_),
embedding_size=FLAGS.embedding_dim,
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))),
num_filters=FLAGS.num_filters,
l2_reg_lambda=FLAGS.l2_reg_lambda)
# 训练步数
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-3)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# 模型的保存目录
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# 损失和准确率的标量
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# 字典保存
#vocab_processor.save(os.path.join(out_dir, "vocab"))
# Initialize all variables
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
训练过程的一步
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
#传入变量,得到变量的返回值
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
# Generate batches
batches = data_helpers.batch_iter(
list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
dev_step(x_dev, y_dev, writer=dev_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
def main(argv=None):
#x_train, y_train, vocab_processor, x_dev, y_dev,pre_weights = preprocess()
train(x_train, y_train, vocab_processor, x_dev, y_dev,pre_weights)
if __name__ == '__main__':
tf.app.run()
tensorflow的训练过程,没有同keras一样简单容易操作,写起来相当复杂,对初学者不友好。我们要将数据处理好,一批一批的送入到定义好的图中,让图运行起来。需要注意的是,tensorflow中步数(global step)是一个计数器,每训练一个batch_size的数据,步数就加一,这样训练一轮(epoch)会有多个步数,是通过计算得来的。另外,函数sess.run()中不仅传入数据,还传入运行过程中需要返回查看的一些值,如accuracy,loss等。
至此,基于tensorflow的cnn文本分类模型介绍结束。模型不难,初学者容易看懂,通过这个学会tensorflow的基本操作,基础的炼丹应该不难了,在学一些热腾腾的模型,以后可以快乐的炼丹了。
现在BERT横扫各大比赛榜单,各种模型都预先使用BERT来提取特征,不会使用BERT,都不好意思说自己是搞深度学习的。所以,这里我稍微介绍一下如何Tensorflow来加载BERT模型。
#初始化BERT model = modeling.BertModel( config=bert_config, is_training=False, input_ids=input_ids, input_mask=input_mask, token_type_ids=segment_ids, use_one_hot_embeddings=False) #加载BERT tvars = tf.trainable_variables() (assignment, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_check_point) tf.train.init_from_checkpoint(init_checkpoint, assignment) #获得BERT的输出[b,s,e] encoder_last_layer = model.get_sequence_output()
获得BERT的输出后,就可以愉快的将BERT输出送入到后续网络层中,进行各种风骚操作了。