CCL“中国法研杯”相似案例匹配评测竞赛主要是针对多篇法律文本进行相似度的计算和判断。具体地,对于每份文书提供文本的标题以及描述事实,需要从两篇候选文集中找到与询问文书更为相似的一篇文书。
从本质上来看,这与二元组匹配任务类似,二元组匹配任务是输入一个元组$<X,Y>$,判断$X$和$Y$是否为同一类样本。代表网络有Siamase network,ESIM,InferSent。这里我们借着这个任务,来介绍一下文本匹配任务以及上述的三个网络模型。
文本匹配任务
在真实场景中,如搜索引擎、智能问答、知识检索、信息留推荐等系统中的召回、排序环节,通常面临如下任务
从大量存储的doc中,选取与用户输入query最匹配的doc。
这里我们可以将上述任务抽象成文本匹配问题,例如信息检索可以归纳成查询文档和文档的匹配,问答系统可以归结成问题和候选答案的匹配,对话系统可以归结成对话和回复的匹配。针对不同的任务选取合适的匹配模型,提高匹配的准确率成为自然语言任务的重要挑战。
常用数据集介绍
论文中常用的数据集:
- SNLI:570k条人工标注的英文句子对,label有三个:矛盾、中立和支持;
- MultiNLI:433k个句子对,与SNLI相似,但是SNLI中对应的句子都用同一种表达方式,但是MultiNLI涵盖了口头和书面语表达,可能表示形式会不同(mismatched)
- Quora 400k个问题对,每个问题和答案有一个二值的label表示他们是否匹配
模型方案
文本匹配模型的现有方案很多,这里主要介绍以下三个:Siamase network,ESIM,InferSent
Siamase network
简单地来说,Siamase network就是“连体的神经网络”,神经网络的”连体“是通过共享权值来实现的。孪生神经网络有两个输入$(input_1,input_2)$,将两个输入送入两个神经网络,这两个神经网络分别映射到新的空间,形成输入在新的空间中的表示,通过Loss的计算,评价两个输入的相似度。如下图所示
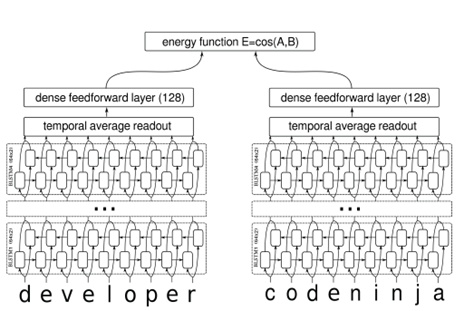
通过两层的双向LSTM作为encoder,左右两边的encoder通过共享权值,然后通过余弦相似度衡量两个sentence的相似情况。
在孪生网络中选择一个好的损失函数至关重要,常用的softmax当然是一种好的选择,但不一定是最优的选择,即使在分类问题中。传统的siamase network 使用 Contrastive Loss。损失函数还有更多的选择,siamase network的初衷是计算两个输入的相似度,左右两个神经网络分别将输入转换成一个“向量”,在新的空间中,通过判断cosine距离就能得到相似度了。cosine是一个选择,exp function也是一种选择,欧式距离也是可以的。训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。这里简单提一下cosine和exp在NLP中的区别。
根据实验分析,cosine更适用于词汇极的语义相似度度量,而exp更适用于句子级别、段落级别的文本相似性度量。其中的原因可能是cosine仅仅计算两个向量的夹角,exp还能保存两个向量的长度信息,而句子蕴含更多的信息。(当然,没有做实验验证这个事情,待验证)。
短文本匹配利器ESIM
ESIM,简称”Enhanced LSTM for Natural Language Inference”。顾名思义,一种专为自然语言推断而生的加强版LSTM。ESIM比其它短文本分类算法厉害之处主要在于两点:
- 精细的设计序列式的推断结构。
- 考虑局部推断和全局推断。
作者是用于句子见的注意力机制(intra-sentence attention),来实现局部的推断,进一步实现全局的推断。
ESIM 主要分为三部分:input encoding, local inference modeling 和inference composition。如下图所示,ESIM是左边一部分:
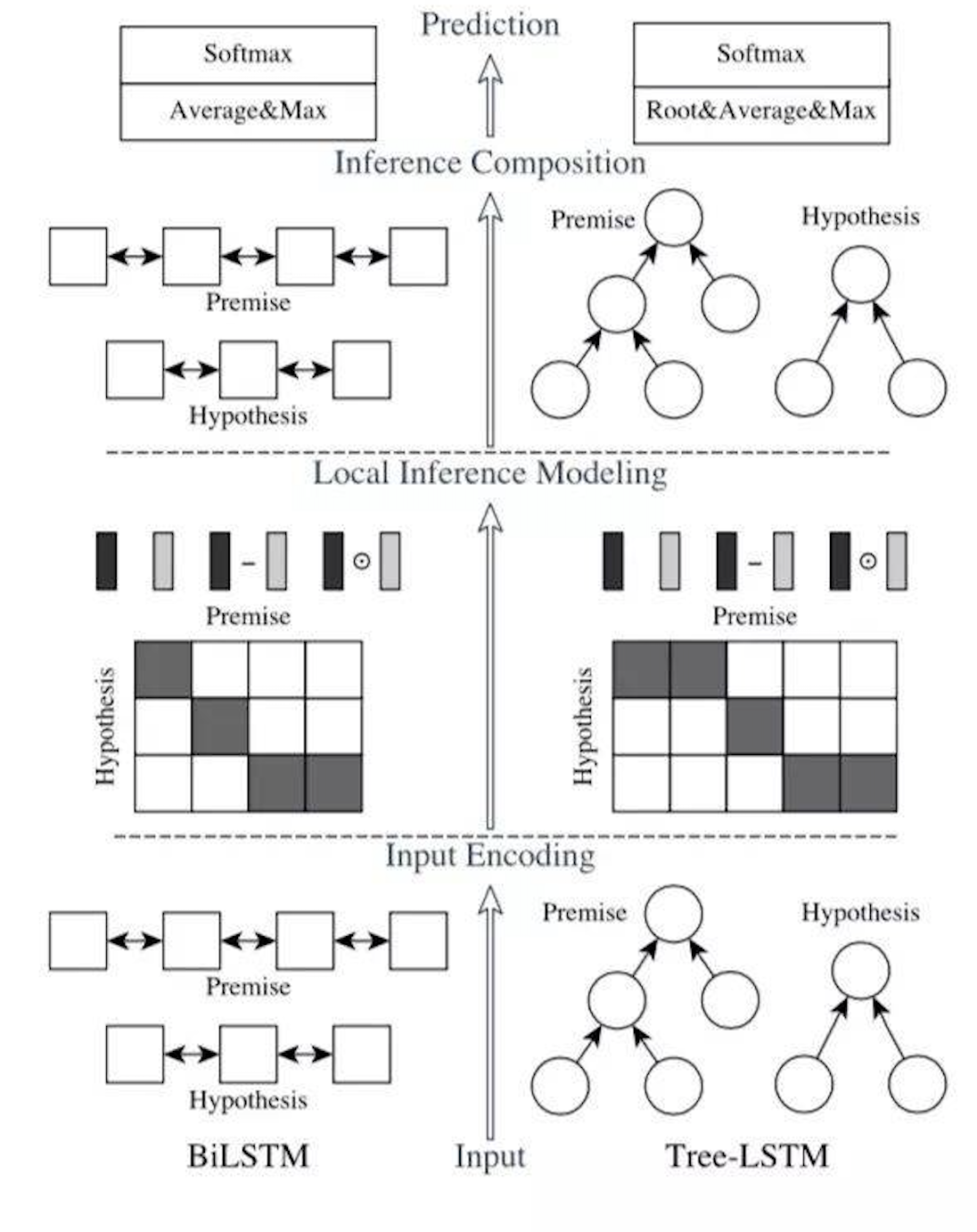
Input encoding
输入部分,就是输入两句话分别接embedding+BiLSTM。这里作者额外提了一句,如果可以做句子的语法分析的话,那么可以使用TreeLSTM。使用 BiLSTM 可以学习如何表示一句话中的 word 和它上下文的关系。
local inference modeling
local inference 之前需要将两句话进行 alignment,这里是使用 soft_align_attention。
然后才进行两句话的 local inference。用之前得到的相似度矩阵,结合 a,b 两句话,互相生成彼此相似性加权后的句子,维度保持不变。
在 local inference 之后,进行 Enhancement of local infere4nce information。这里的 enhancement 就是计算 a 和 align 之后的 a 的差和点积,最后将encoding两个状态的值与相减、相乘的值拼接起来。 体现了一种差异性,作者认为这样的操作更利用后面的学习。
\[m_a = [\bar{a};\tilde{a};\bar{a}-\tilde{a};\bar{a}\odot\tilde{a}]\\ m_a = [\bar{b};\tilde{b};\bar{b}-\tilde{b};\bar{b}\odot\tilde{b}]\]Inference composition
最后一步了,比较简单。再一次用 BiLSTM 提前上下文信息,同时使用 MaxPooling 和 AvgPooling 进行池化操作, 最后接一个全连接层。这里倒是比较传统。
ESIM 的效果很好,作者认为是soft_align_attention起了作用,这一步让要比较的两句话产生了交互。以往的siamase网络中,往往中间都没有交互,只在最后一层求个余弦距离或者其他距离。
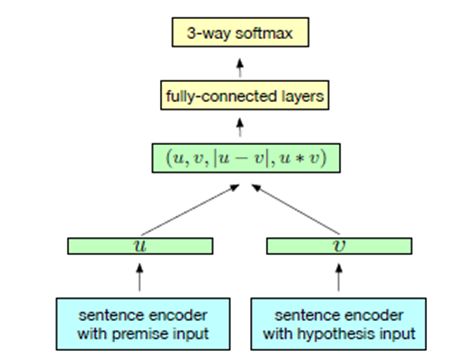
InferSent
Facebook提出了一种InferSent相似度模型,它的基本思想:
设计一个模型在斯坦福SNLI数据集训练,将训练好的模型当做特征提取器,以此来获得一个句子的向量表示,再将这个句子的表示应用在新的分类任务上,来评估句子向量的优劣。
论文中通过不同的encoder得到句子的表征,然后通过两个句子的向量差值,以及两个向量点乘,得到交互向量,最后区分两者的不同。同样地,这里我们也使用BERT作为encoder,然后通过pooling,然后计算Sent A和Sent B的$\mid u-v\mid$以及$u*v$到两者的交互向量,值得一提的是长文本利用InferSent模型可以更好的计算两者的向量相似程度。