Encoder-Decoder
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。
什么是seq2seq呢?简单的说,就是根据一个序列x,来生成另一个输出序列y。seq2seq有很多应用,例如翻译,文档摘要,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
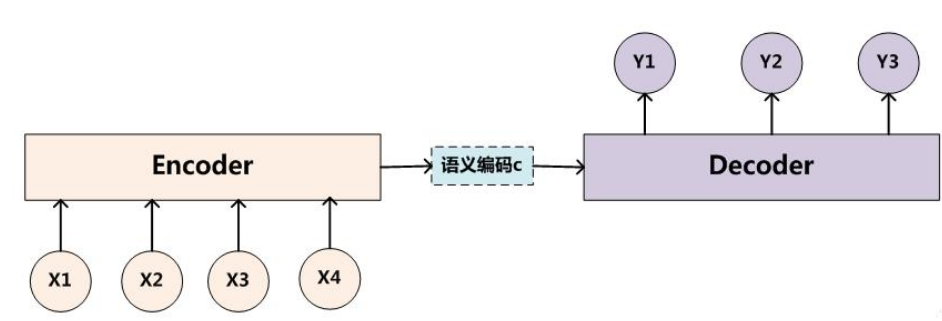
当然了,这个只是大概的思想,具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者编码时使用RNN,解码时使用LSTM等等。
这边为了方便阐述,选取了编码和解码都是RNN的组合。在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,也就是
\[h_t=f(h_{t-1},x_t)\]获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量
\[C=q(h_1,h_2,h_3,...,h_{T_{x}})\]一种简单的方法是将最后的隐藏层作为语义向量$C$,即
\[C=q(h_1,h_2,h_3,...h_{T_{x}})=h_{T_{x}}\]解码阶段可以看做编码的逆过程。这个阶段,我们要根据给定的语义向量$C$和之前生成的输出序列$y_1,y_2,….y_{t-1}$来预测下一个输出的单词$y_{t}$,即
\[y_t=argmaxP(y_t)=\prod^T _{t=1}p(y_t \mid \lbrace y_1,...y_{t-1} \rbrace,C)\]也可以写作
\[y_t=g(\lbrace y_1,...y_{t-1}\rbrace,C)\]而在RNN中,上式又可以简化成
\[y_t=g(y_{t-1},s_t,C)\]其中$s$是输出RNN中的隐藏层,$C$代表之前提过的语义向量,$y_{t-1}$表示上个时间段的输出,反过来作为这个时间段的输入,而$g$则可以是一个非线性的多层的神经网络,产生词典中各个词语属于$y_t$的概率。
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量$C$。也就是说,编码器要将整个序列信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。
Attention模型
为了解决这个问题,提出了Attention模型,或者说注意力模型。简单的说,这种模型在产生输出的时候,还会产生一个‘注意力范围’表示接下来输出的时候要重点关注输入序列的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。模型的大概示意图如下所示
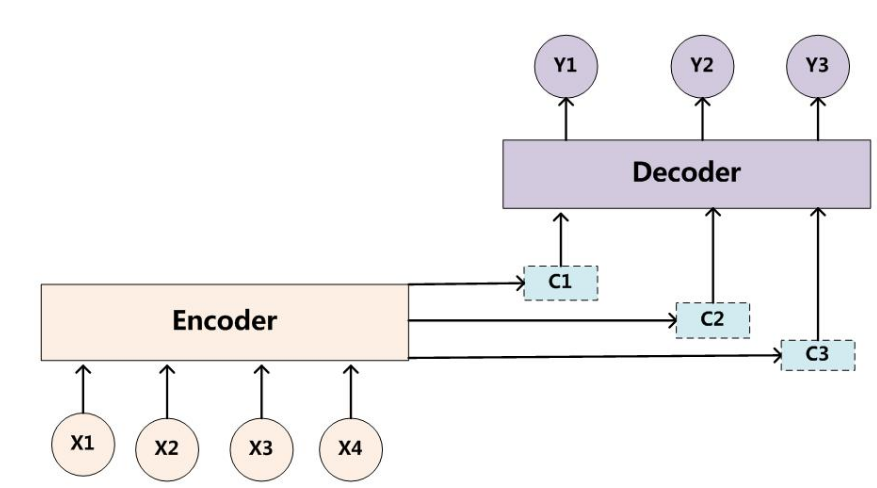
相比之前的encoder-decoder模型,attention的模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的效果。
编码
在单向的RNN中,数据是按顺序输入的,因此在第$j$个隐藏状态$h_j$只能携带第$j$个单词本身以及之前的一些信息;而如果逆序输入,则$h_j$包含第$j$个单词及以后的一些信息。如果把这个两个结合起来,$h_j=[h\to j,h \gets j]$就包含了第$j$个输入和前后的信息。
解码
解码部分使用了attention模型。类似的,我们可以将之前定义的条件概率写作
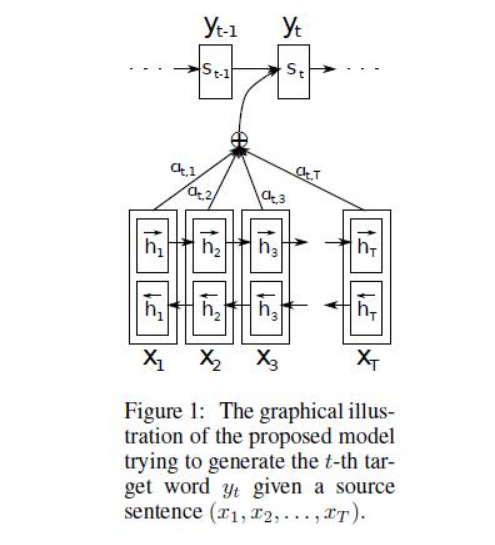
\[p(y_i\mid y_1,...,y_{i-1},X)=g(y_{i-1},s_i,c_i)\]上式$s_i$表示解码器$i$时刻的隐藏状态。计算公式是
\[s_i=f(s_{i-1},y_{i-1},c_i)\]注意这里的条件概率与每个目标输出$y_i$相对应的内容向量$c_i$有关。而在传统的方式中,只有一个内容向量$C$。那么这里的内容向量$c_i$又该怎么算呢?其实$c_i$是由编码时的隐藏向量序列$(h_1,…h_{T_{x}})$按权重相加得到的。
\[c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j\]由于编码使用了双向RNN,因此可以认为$h_i$中包含了输入序列中第$i$个词以及前后一些词的信息。将隐藏向量序列按权重相加,表示在生成第$j$个输出的时候注意力分配是不同的。$\alpha_{ij}$的值越高,表示第$i$个输出在第$j$个输入上分配的注意力越多,在生成第$i$个输出的时候受第$j$个输入的影响也就越大。那么我们现在又有新问题了,$\alpha_{ij}$又是怎么得到呢?这个其实是由第$i-1$个输出隐藏状态$s_{i-1}$和输入中各个隐藏状态共同决定的。也就是
\[\alpha_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\\e_{ij}=a(s_{i-1},h_j)\]也就是说,$s_{i-1}$先跟每个$h$分别计算得到一个数值,然后使用softmax得到$i$时刻的输出在$T_x$个输入隐藏状态中的注意力分配向量。这个分配向量也就是计算$c_i$的权重。我们现在再把公式按照执行顺序汇总一下:
上面这些公式就是解码器在第$i$个时间段内要做的事情。作者还给了一个示意图:
序列中的Attention
Attention机制的基本思想是,打破了传统编码器-解码器结构在编解码结构时都依赖于内部一个固定长度向量的限制。
Attention机制的实现是通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
换一个角度而言,输出序列的每一项的生成概率取决于在输入序列中选择了哪些项。
在文本翻译任务上,使用Attention机制的模型每生成一个词时都会在输入序列中找出一个与之最相关的词集合。之后模型根据当前的上下文向量(context vectors)和之前生成出的词来预测下一个目标词。
…它将输入序列转化为一堆向量并自适应地从中选择一个子集来解码出目标翻译文本。这感觉上像是用于文本翻译的神经网络模型需要‘压缩’输入文本中的所有信息为一个固定长度的向量,不论输入文本的长短。
via:Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
Attention is all you need
Google的一般化Attention思路也是一个编码序列的方案,因此我们也可以认为它跟RNN、CNN一样,都是一个序列编码的层。
事实上Google给出的方案是很具体的。首先,它先把Attention的定义给了出来:
\[Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\]这里用的是跟Google的论文一致的符号,其中\(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\)。 如果忽略激活函数$softmax$的话,那么事实上它就是三个$n\times d_k,d_k\times m, m\times d_v$的矩阵相乘,最后的结果就是一个$n*d_v$的序列。
那怎么理解这种结构呢?我们不妨逐个向量来看。
\[Attention(\boldsymbol{q}_t,\boldsymbol{K},\boldsymbol{V}) = \sum_{s=1}^m \frac{1}{Z}\exp\left(\frac{\langle\boldsymbol{q}_t, \boldsymbol{k}_s\rangle}{\sqrt{d_k}}\right)\boldsymbol{v}_s\]其中$Z$是归一化因子。事实上$q.k,v$分别是$query,key,value$的简写,$K,V$是一一对应的,它们就像是key-value的关系,那么上式的意思就是通过$q_t$这个query,通过与各个$k_S$内积的softmax的方式,来得到$q_t$和各个$v_s$的相似度,然后加权求和,得到一个$d_v$维的向量。其中因子$\sqrt d_k$起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)。
事实上这种Attention的定义并不新鲜,但由于Google的影响力,我们可以认为现在是更加正式地提出了这个定义,并将其视为一个层地看待;此外这个定义只是注意力的一种形式,还有一些其他选择,比如query跟key的运算方式不一定是点乘(还可以是拼接后再内积一个参数向量),甚至权重都不一定要归一化,等等。
多头attention(Mutli-head attention) ,Query,Key,Value首先经过一个线性变换,然后输入到缩放点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数$W$是不一样的。然后将h次的放缩点积attention 结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅计算一次,论文中说到这样的好处是可以允许模型在不同的表示空间里学到相关的信息。
self-attention可以是一般的attention的一种特殊情况,在self-attention中,$Q=K=V$每个序列中的单元和该序列中所有单元进行attention计算。Google提出的多头attention通过计算多次来捕获不同子空间上的相关信息。self-attention的特点在于无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并行可以并行计算。
总结
- 采用传统编码器-解码器结构的LSTM/RNN模型存在一个问题,不论输入长短都将其编码成一个固定长度的向量表示,这使模型对于输入长序列的学习效果很差(解码效果很差)。
- 而Attention机制则克服了上述问题,原理是在模型输出时会选择性地专注考虑输入中的对应相关的信息。
- 使用Attention机制的方法被广泛应用在各种序列预测任务上,包括文本翻译,语音识别等。
参考
深度学习笔记(六):Encoder-Decoder模型和Attention模型
Attention in Long Short-Term Memory Recurrent Neural Networks